Social Media Influence on Stock Price Variabilities
Introduction
Stock price variabilities are nowadays even more affected by positive and negative news. New media channels like Twitter, Facebook, Finance Pages and News Pages, make the news rapidly available and accessible for everybody. It is an enormous amount of distributed data (Big Data), which could no longer be evaluated by a single individual. Powerful and lots of hardware along with suitable systems are needed to gather and interpret this mass of data. With Spring XD (Extreme Spring Data), such a system for big data interpretation and analytics is available. The aim of Spring XD is to facilitate the development of big data applications and to provide an architecture for data acquisition, data processing, data analysis and data export. This article illustrates how positive and negative messages can influence the stock price variability’s implemented with the help of Spring XD. Spring XD Overview Spring XD builts on already existing framework Spring Integration, Spring Data and Spring Batch and allows developers to analyze large amounts of data. Spring XD provides a distributed runtime environemnt, its own domain-specific language (DSL) for configuration and a XD Shell for the administration. Spring XD consists of a server that can be used as single node for the development or in a cluster. As a basic principle to process data Spring XD uses streams. The streams are used to join modules such as data sources (Source) with processing steps (Processor) and data sinks (Sink). Streams are defined by their own DSL. A stream always consists of a source, multiple processors and a sink. The DSL use the same principles as UNIX Pipes (http | mongodb | processor) to configure streams. Spring XD provides a very complete set of modules that can be used by developers to configure their streams. Modules can be used to access file systems, listen on http streams or write data into a HDFS distributed filesystem. The modules (Source, Processor, Sink) that are used in the streams are automatically loaded and registered from the following directory during the start process of Spring XD: \xd\modules. Afterwards the registered modules are available for the stream generation. For the administration of the streams the Spring XD Shell (shell\bin\xd-shell) is available. It allows the creating, starting, stopping, and deleting of streams at run time. XD-Shell command to print all registered modules:
module list
or
module list --type sink
Spring XD Modules
Spring XD provides three kinds of modules: Source, Processor, Sink. Each module has its own module definition. The required fields for a module definition are the name and the type. The name represents the purpose of the modules (e.g. http, twitter, mongodb, …) and the type defines the module like source, sink and processor. To reuse modules in different streams, a module is typically configured by using property placeholders which are bounded to the module’s attributes e.g. the collection name of the mongodb module. To register a new module Spring XD provides a module strategy to find modules based on its name. Therefore Spring XD has default folders to store the modules according to its type:
/modules/source
/modules/processor
/modules/sink
Based on the module type developers create a folder named after the module’s name inside the default type folder and move the xml file to the config directory:
/modules/sink/mongodb/config/mongodb.xml
Additional needed jar files can be placed in the lib directory:
modules/sink/mongodb/
config/
mongodb.xml
lib/
spring-data-mongodb.jar
spring-integration-mongodb.jar
Classes will first be loaded from the above mentioned jar files. Only if they are not found there, they will be loaded from the parent/global Classloader that Spring XD uses. After a restart of the Spring XD node, the new modules are available and can be used for the stream creation. XD-Shell command to manage streams are:
stream all
stream create
stream deploy
stream destroy
stream list
stream undeploy
With the tab key the Spring XD Shell will provide a possible selection of available command parameters. Finance Data Gathering For the stock price variability application the http source is used to access the Yahoo Finance rest API and retrieve the latest stock information. The Twitter Stream API is used to collect the stock price specific relevant messages. To enrich the stock information or stock message data, further source variants (e.g. other finance API’s, other news channels) can be registered to expand the data input. The sources return the data as JSON objects, they are then transformed with processors into an internal format and finally stored in a document-oriented database. The stored data can then be read and displayed graphically via a simple JavaScript based web-application. An overview of the applied components is shown in the following graphic: 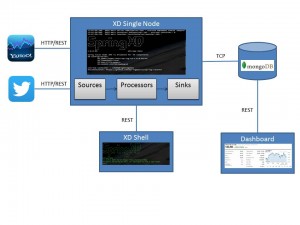 Finance Spring XD Modules Mongo DB Sink Spring XD does not provide a MongoDB sink by default. Since the underlying framework Spring Integration and Spring Data provides Mongo DB support, a Mongo DB sink module can be quite easily generated. The guidelines that should be followed for a module generation can be consulted in the Spring XD documentation. Spring XD configuration for Mongo DB Sink mongodb.xml:
Finance Spring XD Modules Mongo DB Sink Spring XD does not provide a MongoDB sink by default. Since the underlying framework Spring Integration and Spring Data provides Mongo DB support, a Mongo DB sink module can be quite easily generated. The guidelines that should be followed for a module generation can be consulted in the Spring XD documentation. Spring XD configuration for Mongo DB Sink mongodb.xml:
<int:channel id="input"/>
<int-mongodb:outbound-channel-adapter id="mongodbOutboundAdapter" channel="input" collection-name="${collectionName}"/><mongo:mongo host="127.0.0.1" port="28017"/>
<mongo:db-factory id="mongoDbFactory" dbname="financedb"/>
Spring XD module structure for Mongo DB Sink:
modules/sink/mongodb/
config/
mongodb.xml
lib/
spring-data-mongodb.jar
spring-integration-mongodb.jar
Twitter Stock Message Transform Processor For the data acquisition extension additional streams can be added to the system. Since the external systems deliver their data in their own data structure, a transform processor is necessary to bring the data into a unified internal data structure. For each additional data acquisition source a transform processor is necessary. The transform processor can then be applied in the stream creation between the source and sink to perform the conversion. Spring XD configuration for Twitter Transform Processor twitterTransformer.xml:
<int:channel id="input"/>
<int:transformer input-channel="input" output-channel="output" ref="twitterTransformer" method="processMessage"/>
<bean id="twitterTransformer" class="com.mimacom.integration.transformer.TwitterTransformer"/>
<int:channel id="output"/>
Spring XD module structure for Twitter Transform Processor:
modules/processor/twitterTransformer/
config/
twitterTransformer.xml
lib/
finance-1.0.jar
Twitter Stock Message Stream Twitter provides a HTTP Streaming API to retrieve tweets. The result data will be returned as a JSON object. Spring XD already provides a Twitter search source to read the data via the Twitter streaming API. The existing support is used to read the current / latest financial news, which are distributed on Twitter. In the applied source all Twitter messages that contain the words ‘allianz’ and ‘aktie’ will be read. For an accurate analysis these data must be certainly filtered (e.g. text analysis), but this is beyond the scope of this article. In the end the Stream will collect the Twitter messages, transform them into a common data structure and finally store the preprocessed messages in a Mongo DB Collection. Spring XD command for the Twitter Search Stream:
stream create --name twittersearchAllianz --definition "twittersearch --outputType=application/json --fixedDelay=1000 --consumerKey=afes2uqo6JAuFljdJFhqA --consumerSecret=0top8crpmd1MXGEbbgzAwVJSAODMcbeAbhwHXLnsg --query='allianz aktie' | twitterTransformer | mongodb -–collectionName=’twitterAllianz’"
Yahoo Finance Stream Yahoo provides a http finance REST API to retrieve stock market data. The data can be read as XML or JSON Objects. A Spring integration outbound HTTP gateway will be used to read the financial data in a periodic time interval. The time interval is controlled via an inbound channel adapter, which retrieves the data every minute. The Stream will collect the financial data and store it in a Mongo DB Collection. Spring XD configuration for the Yahoo Finance Stream:
<int:inbound-channel-adapter channel="input" expression="''">
<int:poller fixed-delay="60000"></int:poller>
</int:inbound-channel-adapter>
<int-http:outbound-gateway id='ALLIANZGateway'
encode-uri='false'
request-channel='input'
url='http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20yahoo.finance.quotes%20where%20symbol%20in%20%28%22msft,aapl%22%29&diagnotics=false&format=json&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys'
http-method='GET'
expected-response-type='java.lang.String'
charset='UTF-8'
reply-timeout='5000'
reply-channel='output'>
</int-http:outbound-gateway>
<int:channel id="output"/>
<int:channel id="input"/>
Spring XD command for the Yahoo Finance Stream:
stream create allianzStream --definition "trigger | allianz | mongodb --collectionName='stockAllianz'"
Text Analysis
The following part of the blog describes the use of text analysis on top of social media messages to categorize message into positive, negative and neutral ones. The Google Prediction API is used to analyze the message. The Prediction API provides cloud-based machine learning tools to analyze data by pattern-matching and machine learning systems. 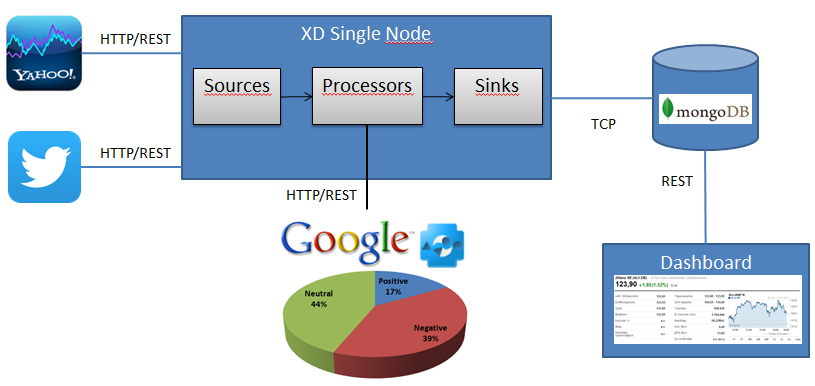 Before categoizing the messages into the mentioned categories via the Predication API, a few issues have to be considered first. Data Collection For a correct text analysis procedure it is necessary to collect a lot of data samples to train the sentimental model. Therefore developers need to train the system against genuine data samples for all the possible categories (positive, negative and neutral). For a convincing model, there are at least several hundred/thousands test examples needed. The test examples have to be provided for all different languages that should be taken into account. Examples:
Before categoizing the messages into the mentioned categories via the Predication API, a few issues have to be considered first. Data Collection For a correct text analysis procedure it is necessary to collect a lot of data samples to train the sentimental model. Therefore developers need to train the system against genuine data samples for all the possible categories (positive, negative and neutral). For a convincing model, there are at least several hundred/thousands test examples needed. The test examples have to be provided for all different languages that should be taken into account. Examples:
- “Allianz is interested to buy …”
- “Allianz discard …”
- “Allianz unchanged …”
Data Labeling: To define the patterns for the machine learning system, we have to label our test samples. The patterns will be used later also for the reporting. Examples:
- “positive”, “Allianz is interested to buy …”
- “negative“, “Allianz discard …”
- “neutral”, “Allianz unchanged …”
Data Preparation The Google Prediction API needs the training data as comma-separated values (CSV) file with one row per example. We can use therefore directly the data labeling format from the data collection examples above. It’s also possible to update and improve the training data afterwards to refine the result. System Feed Developers need to have a google account in order to use the service. To feed the system with the prepared training data, it is necessary to have a google account in order to use the “Google Developers Console (see screenshot below). The “Google Developer Console” is the entry point to create and maintain google application projects. For each project it is possible to activate different google APIs (e.g. Prediction API) and to maintain the application credentials (e.g. OAuth). The credentials allows developers to access the application. To upload the training data files, it’s also necessary to create a “Google Cloud Storage”, which makes the data accessible / available to the applications. 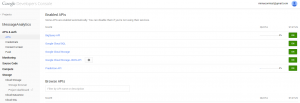 To feed the system with the training data google provides an API Explorer (see below screenshot) to execute REST calls against the corresponding API’s. By using the insert method of the Predication API it is possible to initialize the system with the above created training data file. After finishing the inserting process the predication API is ready to trigger the text analysis. **
To feed the system with the training data google provides an API Explorer (see below screenshot) to execute REST calls against the corresponding API’s. By using the insert method of the Predication API it is possible to initialize the system with the above created training data file. After finishing the inserting process the predication API is ready to trigger the text analysis. ** 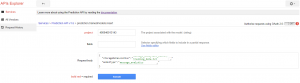 ** Google Prediction Spring XD Processor For the data prediction an additional processor will be added to our processor chain. For each received message data a rest call will be executed to interpret the message classification. The result will be added to our JSON object and evaluated in the web application. Spring XD configuration for Google Predication Processor googlePredictionProcessor.xml:
** Google Prediction Spring XD Processor For the data prediction an additional processor will be added to our processor chain. For each received message data a rest call will be executed to interpret the message classification. The result will be added to our JSON object and evaluated in the web application. Spring XD configuration for Google Predication Processor googlePredictionProcessor.xml:
<int:channel id="input"/>
<int:transformer input-channel="input" output-channel="output" ref="googlePredictionProcessor" method="processMessage"/>
<bean id="googlePredicationProcessor" class="com.mimacom.integration.processor.GooglePredictionProcessor"/>
<int:channel id="output"/>
Spring XD module structure for Google Predication Processor:
modules/processor/googlePredictionProcessor/
config/
googlePredicationProcessor.xml
lib/
finance-1.0.jar
google-api-client-1.19.0.jar
google-api-services-prediction-v.1.6-rev46-1.19.0.jar
google-http-client-1.19.0.jar
google-http-client-jackson2-1.19.0.jar
google-oauth-client-1.19.0-jar
google-outh-client-java6-1.11.0-beta.jar
google-oauth-client-jetty-1.11.0-beta.jar
jetty-6.1.26.jar
Spring XD command for the Twitter Search Stream with Google Predication Processor:
stream create --name twittersearchAllianz --definition "twittersearch --outputType=application/json --fixedDelay=1000 --consumerKey=afes2uqo6JAuFljdJFhqA --consumerSecret=0top8crpmd1MXGEbbgzAwVJSAODMcbeAbhwHXLnsg --query='allianz aktie' | twitterTransformer | googlePredictionTransformer | mongodb -–collectionName=’twitterAllianz’"
Finance and Google Predication Data Presentation
Mongo DB provides a http Rest API. Using an Angular JS application and the mongo js framework for node js developers can read the data via rest calls. In this example we read the stock prices, display it in a stock chart and visualize the rising and falling share prices, and show the financial messages by date and time. Based on the messages potential conclusions can be given on rising and falling stock prices. For the graphical representation Twitter Bootstrap and high Stockcharts is used. With the expanded message data information it is now possible to categorize the messages in the data presentation layer. By interpreting the predication result the messages will be enriched with a positive (green), negative (red), neutral (orange) icon. The predication flag can also be used for complex analysis and calculations. Application with positive prediction message : 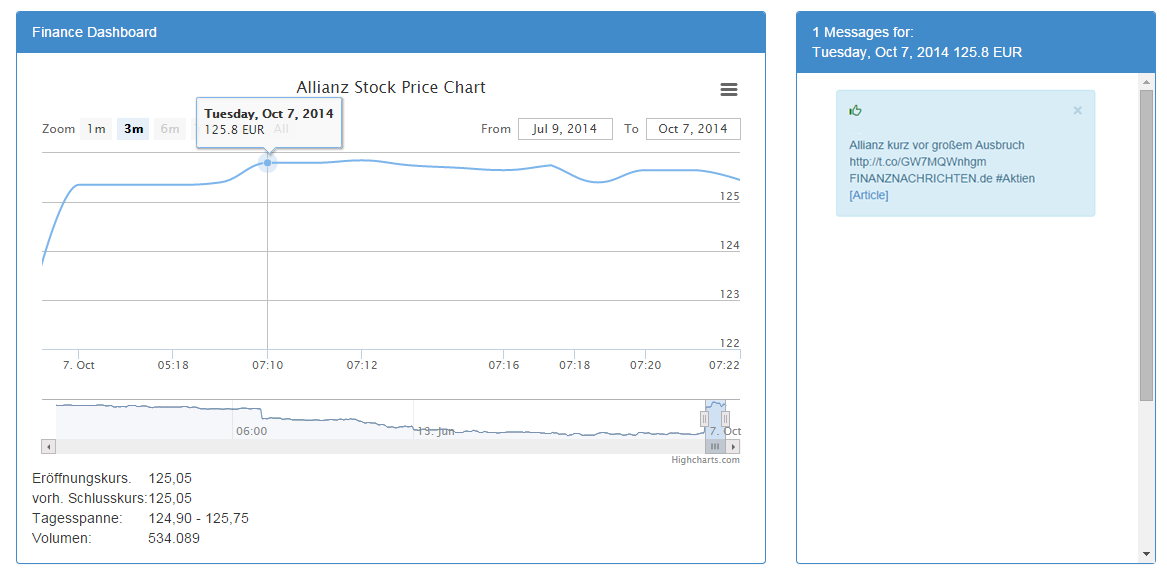 Conclusion This application should demonstrate the basic features of Spring XD. It should demonstrate how easy it is to build processing pipelines with provided Spring XD modules and self-created modules based on the rich support of Spring Integration and Spring Data. The prediction processor integration should demonstrate how easily the processor chain can be expanded and how easy it is to enrich the JSON document with additional information which will be gain by different processors.
Conclusion This application should demonstrate the basic features of Spring XD. It should demonstrate how easy it is to build processing pipelines with provided Spring XD modules and self-created modules based on the rich support of Spring Integration and Spring Data. The prediction processor integration should demonstrate how easily the processor chain can be expanded and how easy it is to enrich the JSON document with additional information which will be gain by different processors.
References
Spring XD Yahoo Finance API Yahoo Query Language Google API Explorer Google Predication API