Autocomplete with Elasticsearch - Part 1: Prefix Queries
You know searches from Google or DuckDuckGo. As you start typing the search engines, give you some autocomplete suggestions.
Let us look into the following example with DuckDuckGo:
As you type ice:
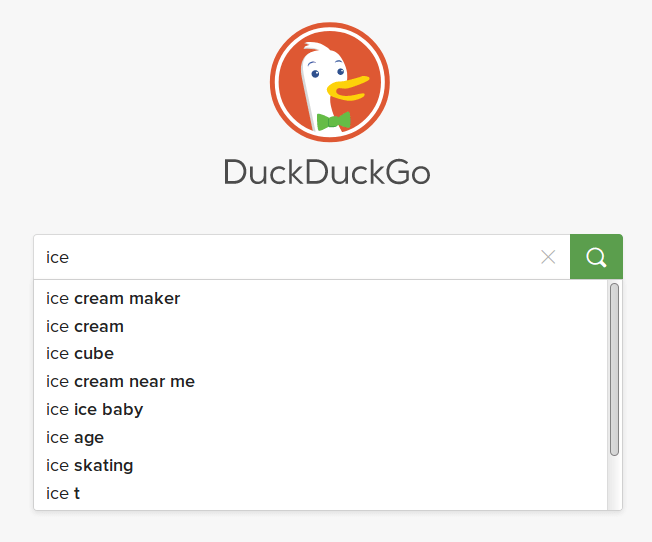
You get suggestions based on popularity like ice cream maker (yay) or some
terms from entertainment like the movie ice age or the rappers ice cube, ice t
alternatively, the sports activity ice skating.
Suggestions, while you type, is a significant strength of Elasticsearch. You can implement it yourself! I am going to explain the various techniques in order of their level of difficulty.
| Method | Difficulty |
| --------------------------------------- | ------------ |
| Prefix and Match Phrase Prefix Query | Easy |
| Index-Time Search-as-You-Type | Intermediate |
| Completion Suggester | Advanced |
This story credit goes again to my co-workers in Job-Room development. If I have to find a new job, I know for sure that I find good suggestions, not necessarily good jobs.
Stats for Nerds
- Estimated reading time ~ 16 Minutes
- The most played song during writing: Ice Ice Baby by Vanilla Ice
- We use Elasticsearch and Kibana v7.1.1
- Photo by Amanda Jones on Unsplash
The autocomplete functionality has many names; some also refer to it as search as you type or type-ahead search. In the end, it enhances the user experience by providing suitable suggestions, to shorten the input or search.
Fight Climate Change: A friend hinted me to the new search engine ecosia. Ecosia uses its profits to plant trees all over the world. I can't verify if everything is legit, however planting more trees is direly needed in consideration to the alarming deforestation worldwide. It seems legit to me.
See below an example of the search suggestion by Ecosia.

Planting trees is a future investment to absorb and store the greenhouse gas, literally to save us all. The impact of deforestation on ecosystems and animal habitat could also have other far-reaching effects which nobody knows or have researched so far. You could start with a simple action to reduce CO2 emissions. Switching your default search engine is effortless. Let's give a try!
Query DSL
The basic idea is to query Elasticsearch for a matching prefix of a word.
A prefix is an affix which is placed before the stem of a word. Adding it to the beginning of one word changes it into another word. For example, when the prefix un- is added to the word happy, it creates the word unhappy.
Source: wikipedia.org
We have to distinguish between
-
The Prefix Query goes on not analyzed text.
-
The Match Phrase Query is a full-text search and therefore analyzes text.
Let us look into one example of what analyzed text means.
GET _analyze
{
"text": ["Average Joe"]
}
The text Average Joe under the analysis of the default analyzer creates 2 tokens: average and joe.
Tokens are all lowercase.
{
"tokens" : [
{
"token" : "average",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "joe",
"start_offset" : 8,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
These tokens go into the inverted index.
Non analyzed text means that the text keeps its original form, i.e. Average Joe in the inverted index.
Elasticsearch has two text types:
text⇒ analyzed textkeyword⇒ not analyzed text
Example Data
To reproduce the example, you can insert the following data against your Elasticsearch endpoint.
POST _bulk
{"index":{"_index":"employees","_id":"3"}}
{"name":"Elvis"}
{"index":{"_index":"employees","_id":"7"}}
{"name":"Average Joe"}
{"index":{"_index":"employees","_id":"11"}}
{"name":"Elisabeth"}
{"index":{"_index":"employees","_id":"13"}}
{"name":"William"}
{"index":{"_index":"employees","_id":"17"}}
{"name":"Jack"}
{"index":{"_index":"employees","_id":"19"}}
{"name":"Iris"}
{"index":{"_index":"employees","_id":"23"}}
{"name":"Barbara"}
{"index":{"_index":"employees","_id":"29"}}
{"name":"Averell Dalton"}
{"index":{"_index":"employees","_id":"31"}}
{"name":"Bryce Dallas Howard"}
{"index":{"_index":"employees","_id":"37"}}
{"name":"Fabio"}
{"index":{"_index":"employees","_id":"41"}}
{"name":"Fabian"}
Prefix Query
As explained, the Prefix Query works only on not analyzed text. Therefore we have to use the keyword text field of name.
We search for the name prefix El.
GET employees/_search
{
"query": { "prefix": { "name.keyword": "El" } }
}
We get Elvis and Elisabeth as results.
{
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "Elvis"
}
},
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "11",
"_score" : 1.0,
"_source" : {
"name" : "Elisabeth"
}
}
]
}
}
Now I use the prefix Eli, and I get only Elisabeth as a result.
What if this was a simple typo and initially I was searching for Elvis?
You can see the limit of a Prefix Query here. It allows no fuzziness.
Combine with Fuzzy Query
Before we use the Fuzzy Query, we introduce the term Fuzziness. In short Fuzziness treats two words that are fuzzily similar as if they were the same word. For instance Mario is with the level of fuzziness 1 character similar to Dario. A very useful feature to handle typos or the case did you mean Dario instead of Mario. We have both in our company :-).
To handle the Elvis case, you have to use the Fuzzy Query.
GET /_search
{
"query": {
"fuzzy": {
"name.keyword": {
"value": "Eli",
"boost": 1,
"fuzziness": 2,
"prefix_length": 0
}
}
}
}
This search request gives us now Elvis.
{
"hits" : [{
"_index" : "employees",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.5972531,
"_source" : { "name" : "Elvis" }
}]
}
However, we are missing Elisabeth now. To get both possible results, we need to transform the query.
GET employees/_search
{
"query": {
"bool": {
"should": [
{ "prefix": { "name.keyword": "Eli" } },
{ "fuzzy": { "name.keyword": { "value": "Eli", "fuzziness": 2, "prefix_length": 0 } } }
]
}
}
}
We now get both results:
{
"hits" : [
{ "name" : "Elisabeth" },
{ "name" : "Elvis" }
]
}
Pay attention on the appropriate level of fuzziness. For instance, we are searching for Elis
GET employees/_search
{
"query": {
"bool": {
"should": [
{ "prefix": { "name.keyword": "Elis" } },
{ "fuzzy": { "name.keyword": { "value": "Elis", "fuzziness": 2, "prefix_length": 0 } } }
]
}
}
}
This fuzzy query yields (simplified):
{
"hits" : [
{ "name" : "Elisabeth" },
{ "name" : "Elvis" },
{ "name" : "Iris" }
]
}
Iris is concerning Elis correct. The fuzziness allows 2 Characters to be different. This name may irritate users. You don't expect a name like Iris to appear if you search for a prefix with Elis.
Summary
Queries like the term prefix or fuzzy queries are low-level queries that have no analysis phase.
They operate on a single term. It is important to remember that the term query
looks in the inverted index for the exact term only; it won’t match any variants like elvis or Elvis.
Match Phrase Prefix Query
The Match Phrase Prefix Query is a full-text query. If you query a full-text
(analyzed) field, Elasticsearch first pass the query string through the
defined analyzer to produce the list of terms to be queried.
Once the query has assembled a list of terms, it executes the appropriate low-level query for each of these terms, and then combines their results to produce the final relevance score for each document.
Source: Elasticsearch - The Definitive Guide 2.x
Now we can use the text field. If we execute the following Prefix Term Query:
GET employees/_search
{
"query": { "prefix": { "name.keyword": "Dal" } }
}
We receive no results. The names are not at the beginning of the not analyzed text.
Now the full-text query comes in handy. We search again for the prefix Dal.
GET employees/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "Dal",
"max_expansions": 10
}
}
}
}
The match_phrase_prefix query search at the beginning of every token and now find our search results.
{
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.6837455,
"hits" : [
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "29",
"_score" : 1.6837455,
"_source" : {
"name" : "Averell Dalton"
}
},
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "31",
"_score" : 1.3419325,
"_source" : {
"name" : "Bryce Dallas Howard"
}
}
]
}
}
No Fuzziness
If you search for the prefix fabi.
GET employees/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "fabi",
"max_expansions": 10
}
}
}
}
Elasticsearch returns Fabio and Fabian:
{
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.334067,
"hits" : [
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "37",
"_score" : 2.334067,
"_source" : {
"name" : "Fabio"
}
},
{
"_index" : "employees",
"_type" : "_doc",
"_id" : "41",
"_score" : 2.334067,
"_source" : {
"name" : "Fabian"
}
}
]
}
}
If you have a typo like Fabion and meant Fabian, the match_phrase_prefix query does not support fuzziness.
You can search now for terms between text with their correct spelt prefix.
Important
The
match_phrase_prefixquery is a poor-man’s autocomplete.
This explanatory note is on the official reference. Only the first 50 terms are relevant for the search in a text field.
For example, the song Hey Jude by the Beatles has 357 tokens if stored into a text field with the english analyzer.
The match_phrase_prefix query cannot cover that to our satisfaction. In most cases, it is sufficient, and in our example, it fits the purpose.
We can overcome that problem by taking another approach in the next article to come.
Please don't try as a workaround to spread the content in 50 tokens each over multiple fields.
Pitfalls
Using both prefix queries have their weaknesses.
Latency
With a growing data-set, you might experience increased latency. There are better performing solutions, which we are going to introduce in the next articles. It depends what you consider as significant data-set based on your underlying resources. A right choice can save you much money for additional resources for your Elasticsearch cluster.
Weak Suggestions
Duplicate results may cause problems in the suggestions. For instance, many job-advertisements have the same job title. Your suggestion list becomes weak if you don't see the other jobs.
You can use a Terms Aggregation query to group job-ads by their job title and filter out results by their prefix.
The following query uses the terms aggregations to build suggestions for the given skills.
GET jobs/_search
{
"query": {
"simple_query_string": {
"query": "java engineer spring angular",
"default_operator": "and"
}
},
"aggs": {
"job_titles": {
"terms": {
"field": "jobtitle.keyword",
"size": 10
}
}
},
"size": 0
}
You get the terms aggregation and the doc count.
{
"hits": {
"total": 136,
"max_score": 0,
"hits": []
},
"aggregations": {
"job_titles": {
"doc_count_error_upper_bound": 2,
"sum_other_doc_count": 96,
"buckets": [
{
"key": "java software engineer",
"doc_count": 7
},
{
"key": "software engineer",
"doc_count": 7
},
{
"key": "java software engineer 80-100% (m/w)",
"doc_count": 5
},
{
"key": "senior software engineer",
"doc_count": 5
},
{
"key": "full stack developer",
"doc_count": 3
},
{
"key": "java software engineer (m/w)",
"doc_count": 3
},
{
"key": "senior software engineer (backend/java)",
"doc_count": 3
},
{
"key": "senior software engineer (frontend/angular)",
"doc_count": 3
},
{
"key": "devops automation lead",
"doc_count": 2
},
{
"key": "full stack web engineer java",
"doc_count": 2
}
]
}
}
}
This workaround causes some server-side processing, and on your client side, you have to process the aggregations instead of the document hits. It is compared to the next methods a very expensive way to do autocomplete suggestions.
Conclusion
- Very easy to use for simple cases
- Your application has to combine search results of prefix and fuzzy query.
- Appropriate for small data-sets.
- Quick results and implementation.
There are more advanced methods which we are going to introduce in the next two articles to come.