DRY Kubernetes with Helm
One of the coolest facets of Kubernetes is the declarative deployment descriptors. You describe what the system should
look like and Kubernetes makes it happen. One of the worst facets of Kubernetes is the declarative deployment descriptors...
A typical system constructed of micro-services will consist of dozens of configuration files, most of which
will be virtually identical to all others. In a relatively small project that I work on we have more than 30
configuration files.
Worse, there may be references between services that are dependent on service names or config map keys. Maintaining this snake pit of configuration files is a potential nightmare.
Taming the snakes with Helm
A popular tool for managing the complexity of Kubernetes configuration is a tool called Helm. A unit in Helm is called a chart.
A chart could describe a complete system, the agreed best practice is to have a chart be a logical set of components.
For example, a chart might contain the configuration for deploying a micro-service and its database along with the services
required for inter-service communication.
Helm is essentially a templating system with values and templates and the values are used to fill out the templates within a chart; generating Kubernetes configuration files. The templating system provides flow structures like loops and if statements which allows different input values to produce quite different configurations. This means a single Helm chart can be used to deploy to CI, integration, local or production environments simply by substituting different values.
Further, charts can contain dependencies/requirements to other charts, or sub-charts. When the parent chart is deployed the sub-charts will also be deployed. Even further, the parent charts can override (and even import) values of the sub-charts.
This chart composition is used by the common "umbrella" pattern where there is a chart per service and there is a parent (or "umbrella") chart that requires all the sub-charts. In this way different projects can share the charts (and thus micro-services) and since each micro-service has a chart, each micro-service can be independently deployed to Kubernetes.
The downside to this pattern is that having a chart per service adds even more configuration files to the system.
Fortunately, Helm can help solve this problem. While sub-charts are not supposed to depend on parent charts, they can
depend on sub-charts. And sub-charts can define templates that can be used by parent charts. Using these two tools it
is possible to create one or more sub-charts designed to be used by the individual service charts. All (or the majority)
of the configuration can be added to a "common" chart and used by the parent charts to make each chart largely DRY.
Once this is done there will be a hierarchy as illustrated below:
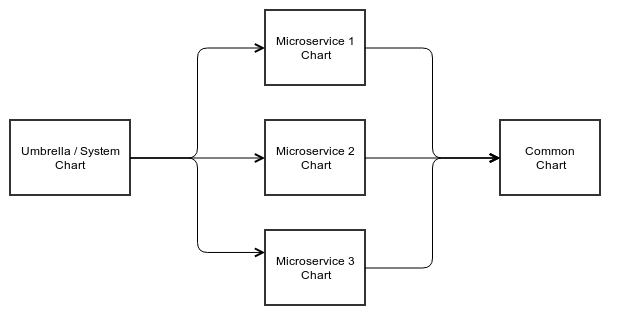
Basic Chart Anatomy
Before one can understand how to create DRY charts we must first take a look at the anatomy of a Helm Chart.
Chart.yaml
values.yaml
requirements.yaml
templates
deployment.yaml
_template.tpl
service.yaml
The Chart.yaml file contains the basic metadata of the chart: name, version, etc...
An example Chart.yaml is as follows:
apiVersion: v1
appVersion: "1.0"
description: Polypoint TPMS Core chart
name: polypoint-tpms-core
version: 0.1.0
The values.yaml file contains the default values used when deploying the chart. There can be multiple values files
and values can also be specified on the command line when installing the chart.
An example values.yaml file:
replicaCount: 1
image:
repository: nginx
tag: stable
pullPolicy: IfNotPresent
The requirements.yaml file defines the sub-charts of the current chart. This includes the sub-chart name, version and
repository. The repository can be a local directory or a Helm repository (a web server). There is more to the
requirements file but for the purposes of this article this is all that you need to know.
An example requirements.yaml file:
dependencies:
- name: core
version: 0.1.0
repository: file://../services/keycloak
- name: keycloak
version: 0.2.4
repository: http://storage.googleapis.com/kubernetes-charts-incubator
The files in the templates directory are the templates used to generate the Kubernetes configuration files.
Important: If one of the files start with an underscore like _helper.tpl then it will not be expected to output text and
is only used to define templates. This is one of the main features we will use to reduce duplicate configuration.
Part of an example _template.tpl file:
{{- define "common.name" -}}
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
{{- end -}}
Part of an example service.yaml file:
apiVersion: v1
kind: Service
metadata:
name: {{ template "common.fullname" . }}
labels:
app: {{ template "common.name" . }}
chart: {{ template "common.chart" . }}
release: {{ .Release.Name }}
heritage: {{ .Release.Service }}
spec:
type: ClusterIP
ports:
- port: 8161
protocol: TCP
name: admin-ui
- port: 61616
protocol: TCP
name: listen-port
selector:
app: {{ template "common.name" . }}
release: {{ .Release.Name }}
The deployment.yaml file would be similar to the service.yaml file so no example is provided here.
Nitty-gritty of Code Sharing
This is but a small part of the configuration that might be needed since Kubernetes could require:
- Pods
- Services
- Volumes
- Namespaces
- ReplicaSets
- Deployments
- StatefulSets
- DaemonSets
- Jobs
Assuming a microservice only contains a deployment and a service there is still a significant amount of configuration.
However, since most micro-services in a project should be quite similar the differences may be primarily the chart name
and perhaps the docker image name. What if you could remove the _template.tpl file and change both the deployment.yaml
file and the service.yaml file to contain a single line like:
{{- template "common.service" . -}}
This can be done by creating a "common" chart containing named templates:
The common chart structure:
Chart.yaml
values.yaml
templates
_deployment.yaml
_template.tpl
_service.yaml
In my example we will assume that each microservice will have a deployment container consisting of a single container and optionally a database container and a single service to allow other services to communicate with the service. In a common chart of an actual project there are likely multiple template files and the parent/microservice chart can choose the templates needed for the particular microservice.
The deployment.yaml file can look as follows (parts have been removed for brevity):
{{- define "common.deployment" -}}
apiVersion: apps/v1
kind: Deployment
{{ template "common.metadata" . }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
app: {{ template "common.name" . }}
release: {{ .Release.Name }}
template:
metadata:
labels:
app: {{ template "common.name" . }}
release: {{ .Release.Name }}
spec:
containers:
{{- $globals := default .Values .Values.global -}}
{{- $required := default false .Values.database.required -}}
{{- if and $globals.database $globals.database.deploydev $required }}
- name: {{ .Chart.Name }}-database
image: "mysql:5.7"
imagePullPolicy: IfNotPresent
ports:
- name: database
containerPort: 3306
protocol: TCP
{{- end }}
- name: '{{ .Chart.Name }}-webapp'
image: '{{ .Values.image.repository }}/{{ template "common.name" . }}:{{ .Values.image.tag }}'
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: {{ default "80" .Values.service.port }}
protocol: TCP
livenessProbe:
httpGet:
path: {{ default "/health" .Values.probes.healthCheckUrl }}
port: {{ default "80" .Values.probes.healthCheckPort }}
{{- end -}}
One salient point in the example above is the line:
{{- if and $globals.database $globals.database.deploydev $required }}
This indicates that if the database is required and the global value .database.deploydev is true then a database
container will be configured for the service. This demonstrates the ability to provide options to the "parent" chart
where the parent chart can enable parts of the configuration by the values it uses.
The _service.yaml file is similar:
{{- define "common.service" -}}
apiVersion: v1
kind: Service
{{ template "common.metadata" . }}
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
protocol: TCP
name: http
{{- $globals := default .Values .Values.global -}}
{{- $required := default false .Values.database.required -}}
{{- if and $globals.database $globals.database.deploydev $required }}
- port: 3306
protocol: TCP
name: db
{{- end }}
selector:
app: {{ template "common.name" . }}
release: {{ .Release.Name }}
{{- end -}
Once again there is an if statement, in this case the if statement controls whether a port for the database is exposed.
Variable Defaults and Per-module Overriding
At this point the templates of each micro-service consists of a single line each, however there are still much duplication
in the values files. The reason for this is how templates are evaluated. If you look at the example of the service.yaml
file in the microservice chart, you will notice the '.' In the line. This is context (or technically the pipeline) that
the template is evaluated within. The (simplified) base pipeline/context is for a chart is:
. Chart
. Release
. Values
. <sub-chart-name>
. <sub-chart-values>
Thus in the sub-chart's templates, when {{ .Values.service.port }} is evaluated (for example) then the service.port is
obtained from the parent/microservice values file. I would prefer that the defaults be obtained from the sub-chart
(common) and be optionally overridden by the parent/microservice chart. This can be done by making all the templates in
the common chart aware that it is a sub-chart. For example to make the _service.yaml template "parent" aware the
first line must be replaced with:
{{- define "common.service" -}}
{{- $common := dict "Values" .Values.common -}}
{{- $noCommon := omit .Values "common" -}}
{{- $overrides := dict "Values" $noCommon -}}
{{- $noValues := omit . "Values" -}}
{{- with merge $noValues $overrides $common -}}
It is assumed that the "common" chart is actually named common. Thus .Values.common refers to the values defined in
the common chart's values.yaml file. This fragment of code takes the common values merges them with the parent's values
(allowing the parent to override the common values) and reconstructs the pipeline/context to use the merged values.
With this change the duplication of the parent is about 1 line per file and any change made to the common chart will be
automatically reflected in all.
Where do we stand?
At this point a project will have a common chart containing base the configuration for deploying one of the projects microservices. Since the templates in the common chart must be explicitly called by the microservice charts, the common chart can have many templates for different situations (ingress configuration, persistent set configurations, secrets, config maps, etc...) and the microservice charts can use the templates it needs and ignore any that don't apply to it.
The common chart's values file will contain all the default values and can be overridden if the microservice chart has particular needs.
The common chart's templates can have if statements allowing microservice charts to have fine-grained control over templates used. Loops (not described in this article) can also be used to allow the microservice charts to add extra ports or environment variables, simply by adding lists to its values file.
Each microservice can have its own chart allowing the microservice to be deployed alone or to be composed in an umbrella chart and be shared between multiple projects. If extra configuration is required that is not provided by the common chart, then the microservice chart can have extra configuration added without impacting the templates obtained by calling named templates in the sub-charts.
Additionally, there can be multiple common charts, each with different templates and "default" values. These templates can be used as needed by the microservice without conflicts (assuming the names are well chosen).
An umbrella chart can be created that is a composition of all the microservice charts required by the system so that the entire system can be deployed, upgraded and withdrawn as a single release and all together.
With all this there is a minimal amount of code duplication. The remaining duplication is primarily in the microservices charts' templates, each of which is a single line. This minor duplication is well worth it as it allows for fine grained inclusions of shared templates and mixing of multiple "common" charts.
In my experience the use of Helm, in the way discussed here, greatly improves the maintainability of Kubernetes configurations and eases deployment and upgrades of systems as well (not discussed in this article but many others). If you are serious about using Kubernetes I highly recommend taking a hard look at Helm.