Using AWS Lambdas to Migrate a Website
When migrating to a new website it is very important to keep all the URLs of the old website alive, by permanently redirecting them to an equivalent page on the new version of the website. Doing so helps to retain the achieved search engine ranking of the old website for the new one.
We have recently relaunched the mimacom website and were faced with migrating more than 3000 unique URLs of more than 10 different domains. The goal was to consolidate the website to www.mimacom.com and to not further serve the website from all other domains. As the new mimacom website is a static website fully hosted on AWS, we were looking for a solution for implementing the redirects with AWS offerings.
Possible Solutions
To handle SSL for the old domains, and of course for high availabilty, we aimed to use CloudFront in front of the redirect implementation. To tackle the actual redirects, we considered three approaches:
Setup a web server
The traditional approach to handle redirects simply is a web server. Depending on the web server, you have some sort of configuration file where you can put the redirects to handle. It is no problem for a web server to handle multiple domains and SSL certificates. However, as our new website is serverless we did not want to introduce a server just for the redirects.
Use S3 redirects
S3 features web page redirects, which the S3 static website hosting turns into HTTP 301 redirects. S3 already has the benefit that the redirects are completely serverless. However, using S3 for the redirects requires to setup an S3 bucket for all the former domains and setting the object metadata to do the redirect at the correct location in each bucket. While this definitely is doable, it involves a lot of state and orchestration. Also, the configuration is spread accross multiple buckets.
Using AWS Lambdas
With Edge Lambdas made generally available in July 2017 it seemed worthwhile to give the lambdas a try. Edge lambdas are written in NodeJS and merely are a callback function that may alter the HTTP response. The lambdas are triggered either on each request, or on each origin lookup. As the lambda should create the redirection HTTP response, executing the lambda on each request is a perfect fit.
Using An Edge Lambda for Website Redirects
To setup the edge lambda for website redirects, we first need to implement a lambda function that takes the current URL as input, checks a map whether there is a redirect defined and finally creates the HTTP redirect response. These three steps are fairly straight forward and without further ado, here is the lambda we use.
The redirects itself are stored in a plain JS object grouped by domain:
'use strict';
const redirects = {
"mimacom.es": {
"/contacto": "/es/acerca",
// ...
}
};
Then, the lambda function first normalizes the requested URL and strips all unneeded characters, extracting the domain and the actual path:
exports.junction = (event, context, callback) => {
const request = event.Records[0].cf.request;
const headers = request.headers;
let url;
// prepare domain, get rid of www if necessary
let domain = headers.host[0].value;
if (domain.startsWith('www.')) {
domain = domain.substring(4);
}
// prepare path: 1) prefix with / 2) remove leading / and 3) remove trailing / from url itself
const path = '/' + request.uri.replace(/^(\/+)/, '').replace(/(\/+)$/, '');
Then, the lambda checks whether a redirect for the requested domain and path are defined in the map and constructs the redirect URL if necessary. If there is no match, the requested URL will simply redirect to the homepage.
// determine redirect
if (domain in redirects) {
if (path in redirects[domain]) {
const redirectTo = redirects[domain][path];
url = `//www.mimacom.com/${redirectTo.replace(/^(\/+)/, '')}`;
console.log(`Redirecting ${domain}${path} to ${url}`);
}
}
// set default redirect if not found
if (!url) {
url = '//www.mimacom.com';
console.log(`Redirecting ${domain}${path} to default: ${url}`);
}
In case you are not consolidating old domains you can simply omit the default and let the request pass through to the origin server. Finally, the HTTP response with the redirect is generated:
// create response
const response = {
status: '301',
statusDescription: 'Moved Permanently',
headers: {
location: [{
key: 'Location',
value: url,
}],
},
};
callback(null, response);
};
We first used the 302 Found status code to redirect during the migration, as 302 represents a temporary redirect which does not alter the index of search engines.
Once we were confident that all redirects were working as expected (and that they were correct also :-) ) we changed the lambda to return the permanent redirect status code 301 Moved Permanently.
Filling the Redirect HashMap
The redirect hashmap has been created manually and was the most time-consuming part of the migration.
Unfortunately, the old website had no /sitemap.xml setup so first, all former domains have been crawled by a script gathering all available pages to a huge CSV file.
In total, there were more than 3000 URLs which were then each manually mapped to a corresponding site of the new website.
As also the contents of the website have changed completely with the relaunch, there was no easy 1-to-1 mapping between the old and new site.
After the mapping has been tediously created, we wrote a script to automatically generate the JS hash map for the edge lambda. With the script, it is also easy to update and maintain the huge edge lambda hash map.
Setting up the Redirect Edge Lambda in AWS
The architecture of the AWS redirect edge lambda looks as follows:
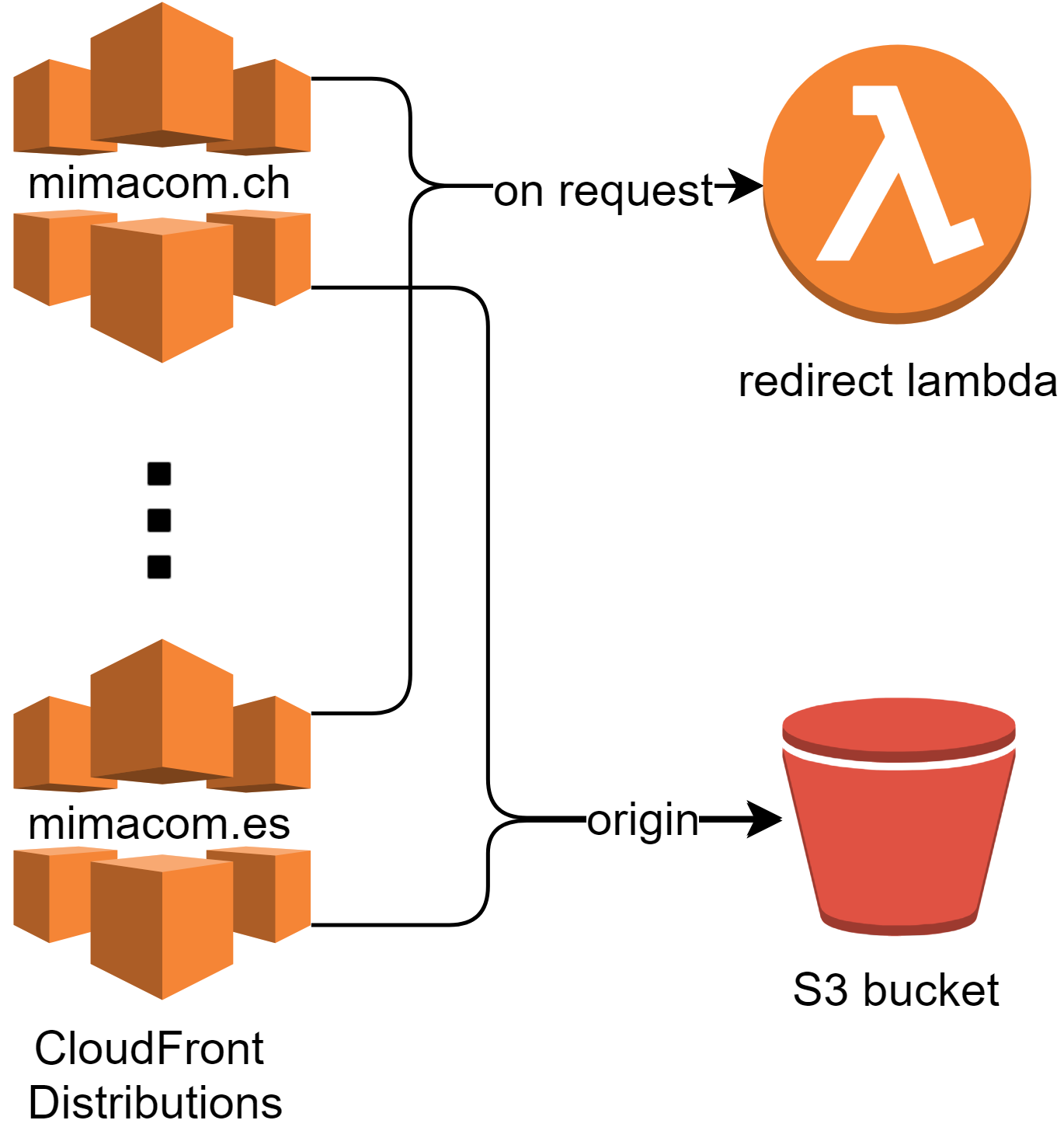
For each domain, we set up a CloudFront distribution referencing the respective Amazon-issued SSL certificate. Each distribution then references the same redirect lambda on the viewer request event, so that there is a single place to update the redirect mapping for all domains. As each distribution requires an origin, there is an empty S3 bucket serving that purpose. Of course, the origin S3 bucket is never reached because the Edge lambda always directly returns a response.
Testing the Redirects with sireg
Now that the redirects are in place, we need to test whether they really are working as expected. To test the redirects, we used sireg, which is a tool for website regression testing. We used our CSV file with the redirect mapping and transformed that into the sireg test case format.
// mimacom-all-urls.json
{
"testCase": "mimacom.*: test all redirects",
"loaders": [
{
"loader": "csv",
"options": {
"filePath": "mimacom-all-urls.csv"
}
}
]
}
and the CSV file containing the actual URLs to be tested simply is:
// mimacom-all-urls.csv
"url","expectedUrl"
"http://mimacom.es/","http://www.mimacom.com/es/"
"http://mimacom.es/aviso-legal","http://www.mimacom.com/es/aviso-legal/"
"http://mimacom.es/carrera","http://www.mimacom.com/es/carrera/"
// ...
The test case can then be execute with sireg by issuing sireg test mimacom-all-urls.json, which requests all 3000 redirects and sees if they point to the expected location.
Being able to automatically test the redirects turned out to be very useful, especially to regression test all redirects after changing the edge lambda.
Conclusion
With Edge lambdas it is very easy to write a small function taking care of redirecting old website URLs to a relaunched version. And being serverless makes the maintenance of the setup very easy, as the traffic on the old URLs and domains will certainly decrease once the search engine index is updated.