Microservices (part 1)
What is a microservices architecture? The microservices architecture pattern consists in functionally decompose a project into a set of collaborative services. Each service will take care of a concrete functionality, a concrete domain. Services will be developed independently, avoiding coupling between them. If needed, services can communicate through an exposed API, using HTTP/REST calls, for instance. Using this approach, multiple developers can work on the same project in a more independent way. Each service will have its own database (schema or set of tables) which will not be accessed by any other service, keeping each service 100% independent from each other. It is possible to have more than one instance of each microservice, making the scalability of the application much easier and avoiding any impact on the deployed application, as explained below. Let's see how it works with an example. Imagine an application where we have Users that can log into the system, which can manage either Universities or Schools, but not both; and these Schools will have Students. Students will also have other relationships but for simplification purposes, that part has been skipped. Last but not least, every School will belong to a University. A simplified data model would look like:
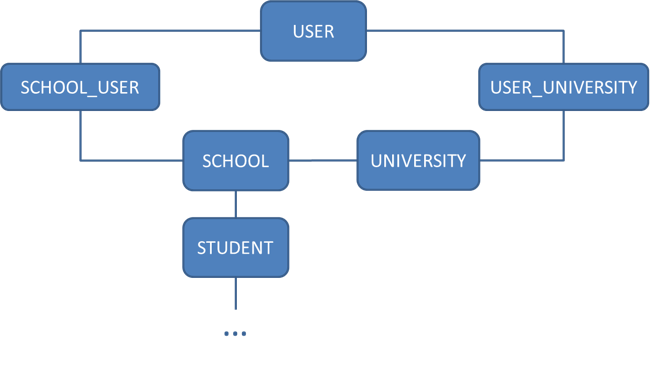
Simplified data model
As said before, each service accesses a set of tables that are only accessible by the service they belong to. Therefore, looking at the requirements and at the data model, now it is possible to define the (micro)services that will define the application. The next image displays the separation of the services and the tables they manage in the database:
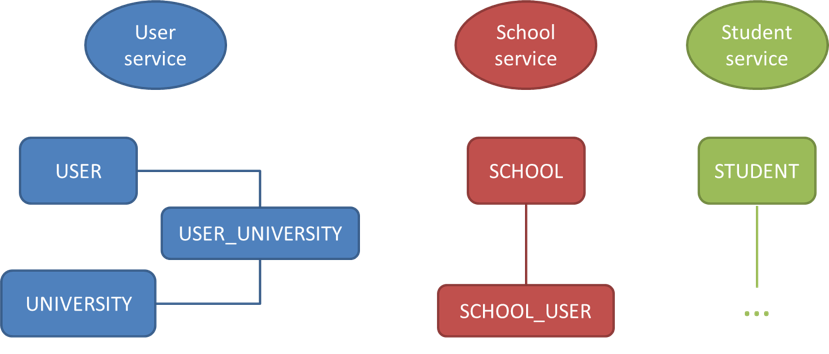
Definition of microservices
Since a concrete table cannot be accessed by two different services, what does it happen when a relationship between two different services exists, such as the user-school relationship? Someone can think of having the user-school relationship also maintained in the user service, as it has been done with the user-university relationship. But the user-university relationship is different because a university does not have any other relationship with other tables in the model. In the case of the schools and users, this is maintained in the school service because a user not necessarily needs to be assigned to a school, it can be linked to a university. But a school will be always related to a user, unless it has no users, which is a very rare scenario. In summary, the application will have three separated services: user, school and student, and they need to interact between each other. Before jumping into how this interaction or communication is done, the next step is to configure every service independently.
Config server
Spring Cloud provides a config server which externalizes the configuration of a project into an external repository. This way, each service can have its configuration in a GIT repository which centralizes the configuration across all environments. It decouples the configuration from the implementation being possible to update the configuration without impacting any of the services. Every update on the configuration files in the GIT repository is automatically propagated to the running instances. Each microservice will connect to this config server on startup to get the values for their configuration. The config server can be registered in Eureka (explained later in this post) or can either be directly configured in each of the microservices. To start using the Spring config server it is necessary to have a GIT repository with the configuration files (locally or remotely) and to download the required dependency using the preferred dependency management tool. This example will use Maven, and first of all it is needed to include the parent pom so it takes care of the versions of every other project shown in this example:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-parent</artifactId>
<version>1.0.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
And here it is the dependency for the Spring cloud config server:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
Next step is to create a Java class to configure the server, which only needs to add the annotation @EnableConfigServer. Please note that this example also uses Spring boot.
@SpringBootApplication
@EnableConfigServer
public class ConfigApplication {
public static void main(String\[\] args) {
SpringApplication.run(ConfigApplication.class);
}
}
The rest of the configuration is placed in a properties o YAML file, as shown in the following picture:
spring:
cloud:
config:
server:
git:
uri: URL to the GIT repository
# for secured GIT repositories username:
password:
searchPaths: name of the subfolder (if needed)
If the GIT repository is secured by username and password, Spring cloud config server provides an encryption and decryption tool so we can secure the user and password in the properties file. Last, the services need to know the location of the Spring cloud config server. Each service needs to have a bootstrap.yml or bootstrap.properties file with the following configuration:
spring:
application:
name: school
cloud:
config:
uri: http://localhost:8001
profiles:
active: dev
Where spring.application.name is the name of the microservice, which is needed to define the configuration files in the repository, spring.cloud.config.uri is the URL of the config server and profiles.active is the list of active profiles. And also the main class of the service needs to use the annotation @EnableAutoConfiguration to connect to the config server.
GIT repository
As shown in the next points, the configuration files of the microservices will be stored in a GIT repository, which can be local or remote. Same rules as with standard Spring Boot application applies with these configuration files.
How do microservices communicate?
As said before, the user service and the school service need to share some information but they are not allowed to read/write from/to a shared table in the database. Microservices can expose an API to let other services can make calls against it. So let's think that the school service provides an API to add or remove the assignment of a user with a school, to retrieve a list of schools assigned to a user, etc. First of all, since user and school services are totally decoupled, how does the user service know where is the school service located? Ok, we can set up the URL of the service in the configuration file. But what if that URL often changes or there are multiple instances of the school service deployed? This can be solved by using a Service Discovery Server: Eureka.
Eureka
Eureka is a service discovery server and client. A client registers with Eureka providing its name and some metadata, such as the host, port, health indicator URL, etc. Eureka receives a heartbeat to detect if an instance or a service is down, in which case Eureka normally removes the service/instance from the registry. Multiple instances of Eureka server can be deployed and all of them will provide to each other the health status of all the registered instances.
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String\[\] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
A client that wants to register with Eureka needs to annotate the main class with @EnableDiscoveryClient and also configure the Eureka server URL, as shown below:
eureka:
instance:
metadataMap:
instanceId: ${spring.application.name}:${random.value}
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/ #URL of Eureka server
The key eureka.instance.metadataMap.instanceId defines the name of the instance that will be registered with Eureka. If it is needed to have multiple instances this value must be random, otherwise every time all instances will be registered with the same instanceId, meaning that only one will be available. Each Eureka client will register with the Eureka server on startup and the server will check the health status of each service and instance, removing the dead ones if needed to avoid failures in the application. Once the services are registered with Eureka they can connect to each other throughout it so the last step to establish a communication between two services is to build a client. In this example Feign will be used to build the client.
Feign
Feign is a declarative web service client. Writing a REST client is much easier with Feign and together with Spring cloud, it only requires to add the annotation @EnableFeignClients to the main class and to define the client as it is shown in the following code snippet:
@FeignClient("school")
public interface SchoolClient {
@RequestMapping(value = "/school/user/{userId}", method = RequestMethod.GET)
List getAssignedSchools(@PathVariable(value = "userId") Long userId);
@RequestMapping(value = "/school/{schoolId}/user/{userId}", method = RequestMethod.PUT)
void assignUserToSchool(@PathVariable(value = "schoolId") Long schoolId, @PathVariable(value = "userId") Long userId);
}
As shown in the figure, building a REST client with Feign only needs an interface annotated with the @FeignClient annotation with the name of the service registered in Eureka as a parameter, and the request mappings of the API methods. Something really important to be aware of when establishing relationships between services is the idempotency of the methods. In a general application, concretely built with Spring, we can use the annotation @Transactional to provide this idempotency to methods that persist data. When having a method that makes a REST call to another microservice, @Transactional cannot be used to take care of rollbacks in case of error. This must be done manually. It may happen that the service to be called is not available, so the method should be implemented in a way where the call could be triggered again without any conflict with the existing data. How can this be achieved? First, this only applies to methods that actually modify or persist data, therefore GET requests are not being considered (if getAssignedSchools() fails it can be triggered again without any conflict with the data). In the case of requests that persist or modify data, such as POST and PUT requests, they should be done in a idempotent manner. As an example: The process to create a user who is assigned to a school would be:
- Create the user (insert new row into the table USER)
- Assign it to a school (call the School service to assign the recently created user to the given school)
If a POST method is used for the step 1, and the userId is autogenerated by the database, but the step 2 fails, the method will end up creating a user without any school assigned. If the request is triggered a second time, a new user would be created meanwhile this should not happen as the user has been already inserted. How can modify this behavior? Sending the userId together with the request and using a PUT instead of a POST. The userID can be a uuid generated in the ui application or the ui application can make a REST call to the server first to retrieve the id to be used, therefore the request will always have the same userId and if the request is triggered twice or more times the user will not be created twice. Spring-retry can be used to define and manage the scenarios where a service call fails and a retry is needed. To sum up, this example has shown a microservices architecture, how to maintain the configuration in a centralized way and how two or more services communicate between each other. But there are other open issues such as:
- How to add security to microservices?
- How to define fallback actions when an instance or a service is down? Is it possible to see metrics of them?