I Am Your Father - Parent-Child Modeling in Elasticsearch
«No! That's not true! That's impossible!»
In 1980, The Empire Strikes Back revealed that Darth Vader was Luke's father, a twist that has become one of the most iconic or shocking movie moments to that time in movie history. It is one IMHO of the best movies in the Star Wars franchise of all time.
The parent-child relationship within the Elasticsearch universe can also be shocking if you have noticed the impact of the removal of mapping types in Elasticsearch. We are looking at the relationship from the supported versions (Elasticsearch v5.x) to the current present and announced changes of the future. This design is an advanced method of document modelling in Elasticsearch.
Stats for Nerds
- Beverages
- Coffee: 6
- Tea: 2
- Article Stats
- time spent working: 6 hours
- time spent writing: 2 hours and 14 minutes
- word count: 2655
- estimated reading time (200 words per minute): 13 minutes and 16 seconds
- Most played songs:
- You Get What You Give by the New Radicals
- All of Me by John Legend
- Space Age Love Song by A Flock of Seagulls
- Story origin:
- This article originates from a technical discussion between our software engineers.
- This blog article is a summary of recipes for the implementation with parent-child relationships.
- Story details:
- IMHO stands for in my humble opinion.
- John Roger Stephens, known professionally as John Legend, is an American singer and songwriter.
Data Modeling for Elasticsearch
Elasticsearch is not a relational database. If you come from relational databases or SQL background, you need to change your thought process for modelling data concerning Elasticsearch. In SQL, you typically normalise your data. Elasticsearch is about search. Search requires different considerations. In Elasticsearch, you typically denormalise your data!
A flat world has its advantages :
- Indexing and searching is fast
- No need to join tables or lock rows
Elasticsearch is about search efficiency, not storage efficiency.
Relationships Matter
Four common techniques exist for managing relational data in Elasticsearch:
- Denormalizing: Flatten your data
- Application-side joins: Run multiple queries on normalised data
- Nested objects: Store arrays of objects
- Parent-child relationships: Store multiple documents through joins
As long as you understand the tradeoffs of each technique, there's no difficulty to use it. We are going to look in detail about the parent-child relationship or in-depth grandparents and grandchildren. Sometimes relationships matter. It depends on your case.
The Problem
For the general audience to understand the challenges we might face, I am going to use examples to illustrate the parent-child relationship. The examples are a work of fiction. Names, characters, places and incidents either are products of the author’s imagination or are used fictitiously. Any resemblance to actual events or locales or persons is entirely coincidental.
Let us look into the following situation. Assuming we have a social music service. We store information about artists, their songs and the likes from users to measure their popularity. This model would result in the following relationship hierarchy.
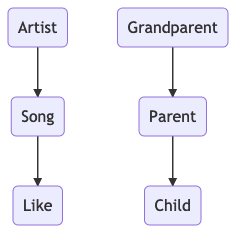
Let's look into one complex example:
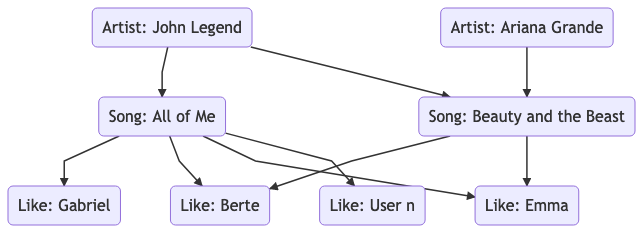
- An artist may have zero to many songs.
- John Legend has two songs.
- Ariana Grande has one song.
- One or multiple artists perform a duet.
- Beauty and the Beast is performed by John Legend and Ariana Grande.
- John Legend performs All of Me.
- Many users can like a song.
- Gabriel, Berte and Emma liked the song All of Me.
- Berte and Emma also liked the song Beauty and the Beast.
Another information of interest is the count of plays of each song by the respective user. I am leaving that detail out because it does not provide more value for the explanation.
Other Examples
There are many examples, which also suits the parent-child demonstration.
Talent Management
If you want to keep track of your talents (employees), try for instance Talent Management with Elasticsearch.
Job Ads
Matchmaking between Workers and Employers.
Team Composition
A football (soccer) team.
Benefits of Parent-Child Relationships
A parent-child relationship in Elasticsearch results in two documents that remain on the same index, or better index shard. You can't split parents and children into two separate indices.
- The parent document and children are entirely separate documents
- The parent document can be updated without reindexing the children
- Child documents can be added, changed, or deleted without affecting either the parent or other children.
- This circumstance is especially useful when child documents are large in number and need to be added or changed frequently.
- Child documents can be returned as the results of a search request.
The only case where the parent-child relationship makes sense is if your data contains a one-to-many relationship where one entity significantly outnumbers the other entity. The song (parent) won't change, but the likes (children) for that song may grow steadily.
If you would use a nested object for the above use case, the update is expensive. Updating a nested object requires a complete reindexing of the root object and a complete reindexing of all its nested objects!
Technical Facts
As mentioned above the parent and the children must live on the same shard. This physical constraint makes the query-time join faster if a search for the parent or child occurs.
The relationship join lives inside the memory. Each join, has_child or has_parent query adds a significant tax to your query performance.
Using Parent-Child Relationships
To use parent-child relationships we give you some examples with the Elasticsearch REST API. Use the Kibana Console (previously known as Marvel Sense) to execute the examples.
- Define the mapping
- Index some parent documents
- Index some child documents
- Query the documents
We have two indices:
- The data for parent-child relationships before version 5.6 is in index
music. - The data for recent Elasticsearch versions is in index
music-5_6.
Mapping (before version 5.6)
If you are using an Elasticsearch version less than 5.6 read this section, else skip to the next section.
Parent-child documents have different mapping types. See below the index mapping.
PUT music
{
"settings": { "number_of_shards": 1, "number_of_replicas": 0 },
"mappings": {
"artist": {
"properties": { "name": { "type": "text" }}
},
"song": {
"properties": { "title": { "type": "text" }},
"_parent": { "type": "artist"}
},
"likes": {
"properties": { "user": { "type": "keyword" }},
"_parent": { "type": "song"}
}
}
}
To declare the parent we reference the (mapping) type of the parent. In the above example, the parent for song is artist.
Mapping (after version 5.6 to version 6.x)
Version 5.6 introduces a new field join type to declare parent-child relationships. We have to prevent multiple mapping types in order to use the join type. This mapping type setting allows us to easily upgrade the Elasticsearch index to Version 6 without any impacts or side-effects.
In the index settings we set "mapping.single_type": true. You don't need this setting if you are using an Elasticsearch version greater than 5.6. Elasticsearch 7 completely removes the mapping type information.
PUT /music-5_6
{
"settings": {
"number_of_shards": 1, "number_of_replicas": 0,
"mapping.single_type": true
},
"mappings": {
"doc": {
"properties": {
"artist": { "type": "text" },
"song": { "type": "text" },
"user": { "type": "keyword" },
"artist_relations": {
"type": "join",
"relations": {
"artist": "song",
"song": "user"
}
}
}
}
}
}
Using multiple levels of relations to replicate a relational model is not recommended. Each level of relation adds overhead at query time in terms of memory and computation. Each index may have only one join field, where all relations are declared. The artist_relations field on the above example is that join field.
Index data (ev < v5.6)
If you are using an Elasticsearch version less than 5.6 read this section, else skip to the next section.
Index artists (parents)
POST /music/artist/_bulk
{ "index": { "_id": "john-legend" }}
{ "name": "John Legend" }
{ "index": { "_id": "ariana-grande" }}
{ "name": "Ariana Grande" }
Index songs (children) and assign the respective parent
POST /music/song/_bulk
{ "index": { "_id": 1, "parent": "john-legend" }}
{ "title": "All of Me" }
{ "index": { "_id": 2, "parent": "john-legend" }}
{ "title": "Beauty and the Beast" }
{ "index": { "_id": 3, "parent": "ariana-grande" }}
{ "title": "Beauty and the Beast" }
Pay attention that the song Beauty and the Beast (a duet of John Legend and Ariana Grande) has two documents. This situation illustrates another issue. In an Elasticsearch parent-child relationship, a child can not have multiple parents. To comply with the example, we created two song documents and assigned each to both artists.
Index user likes to song (grandchildren).
POST /music/likes/_bulk
{ "index": { "_id": "l-1", "parent": 1 }}
{ "user": "Gabriel" }
{ "index": { "_id": "l-2", "parent": 1 }}
{ "user": "Berte" }
{ "index": { "_id": "l-3", "parent": 1 }}
{ "user": "Emma" }
{ "index": { "_id": "l-4", "parent": 2 }}
{ "user": "Berte" }
{ "index": { "_id": "l-5", "parent": 3 }}
{ "user": "Emma" }
Index data (ev > v5.6)
To index parents with the join field, we have to specify its relation type.
POST /music-5_6/doc/_bulk
{"index":{"_id":1}}
{"name":"John Legend","artist_relations":{"name":"artist"}}
{"index":{"_id":2}}
{"name":"Ariana Grande","artist_relations":{"name":"artist"}}
We can only index child documents with the respective parent. The parent is additionally used in the routing information, since as you can remember parent and child must reside on the same shard. The parent’s id serves as the routing value for the child document.
PUT music-5_6/doc/3?routing=1
{"song":"All of Me","artist_relations":{"name":"song","parent":1}}
PUT music-5_6/doc/4?routing=1
{"song":"Beauty and the Beast","artist_relations":{"name":"song","parent":1}}
PUT music-5_6/doc/5?routing=2
{"song":"Beauty and the Beast","artist_relations":{"name":"song","parent":2}}
To index the likes. A bulk request for the song All of Me.
POST music-5_6/doc/_bulk?routing=3
{"index":{"_id":"l-1"}}
{"user":"Gabriel","artist_relations":{"name":"user","parent":3}}
{"index":{"_id":"l-2"}}
{"user":"Berte","artist_relations":{"name":"user","parent":3}}
{"index":{"_id":"l-3"}}
{"user":"Emma","artist_relations":{"name":"user","parent":3}}
Simple Indexing for grandchildren
POST music-5_6/doc/l-4?routing=4
{"user":"Berte","artist_relations":{"name":"user","parent":4}}
POST music-5_6/doc/l-5?routing=5
{"user":"Emma","artist_relations":{"name":"user","parent":5}}
Finding Children by their Parents
Now if we want to know, how many songs for John Legend exists, we use the has_parent query. Therefore we search in the mapping type song.
 Photo by Daniel Cheung on Unsplash
Photo by Daniel Cheung on Unsplash
Version < v5.6
If you are using an Elasticsearch version less than 5.6 read this section, else skip to the next section.
GET /music/song/_search
{"query":{"has_parent":{"type":"artist","query":{"match":{"name":"John Legend"}}}}}
The above search request let Elasticsearch return these songs:
{
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "music",
"_type": "song",
"_id": "1",
"_score": 1,
"_routing": "john-legend",
"_parent": "john-legend",
"_source": {
"title": "All of Me"
}
},
{
"_index": "music",
"_type": "song",
"_id": "2",
"_score": 1,
"_routing": "john-legend",
"_parent": "john-legend",
"_source": {
"title": "Beauty and the Beast"
}
}
]
}
}
Search for all user-likes of a song.
GET /music/likes/_search
{"query":{"has_parent":{"type":"song","query":{"match":{"title":"all of me"}}}}}
Version >= v.5.6
Search for all songs (child) of an artist (parent).
GET music-5_6/_search
{
"query": {
"has_parent": {
"parent_type": "artist",
"query": { "match": { "name": "John Legend" } }
}
}
}
Elasticsearch yields this resultset:
{
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "music-5_6",
"_type": "doc",
"_id": "3",
"_score": 1,
"_routing": "1",
"_source": {
"song": "All of Me",
"artist_relations": { "name": "song", "parent": 1 }
}
},
{
"_index": "music-5_6",
"_type": "doc",
"_id": "4",
"_score": 1,
"_routing": "1",
"_source": {
"song": "Beauty and the Beast",
"artist_relations": { "name": "song", "parent": 1 }
}
}
]
}
}
Search for grandchildren, in our example, search for all user-likes (grandchild of the artist) of a song (child of the artist).
GET music-5_6/_search
{
"query": {
"has_parent": {
"parent_type": "song",
"query": {
"match": { "song": "all of Me" }
}
}
}
}
Elasticsearch returns this response:
{
"hits": {
"total": 3, "hits": [
{
"_source": { "user": "Gabriel", "artist_relations": { "name": "user", "parent": 3 }}
},
{
"_source": { "user": "Berte", "artist_relations": { "name": "user", "parent": 3 }}
},
{
"_source": { "user": "Emma", "artist_relations": { "name": "user", "parent": 3 }}
}
]
}
}
Finding Parents by their Children
The has_child query and filter can be used to find parent documents based on the contents of their children.
Searching for all artists (parents) that have one to ten (min_children and max_children) songs.
GET music/_search
{
"query": {
"has_child": {
"type": "song",
"min_children": 1, "max_children": 10,
"query": { "match_all": {} }
}
}
}
This will return:
{"hits": {"total":2,"hits":[
{"_index":"music","_type":"artist","_id":"john-legend","_score":1,"_source":{"name":"John Legend"}},
{"_index":"music","_type":"artist","_id":"ariana-grande","_score":1,"_source":{"name":"Ariana Grande"}}]}
}
Return Parents and Children
Having the artists we know that have songs, but we do not know which songs caused the hit.
Use the inner_hits query to get the relevant children from the has_child query.
GET music/_search
{
"query": {
"has_child": {
"type": "song",
"min_children": 1, "max_children": 10,
"query": { "match_all": {} },
"inner_hits": {}
}
}
}
This response shows the artists with their songs.
{"hits":{"total":2,"hits":[
{"_source":{"name":"John Legend"},"inner_hits":{
"song":{"hits":{"total":2,"hits":[
{"_source":{"title":"All of Me"}},
{"_source":{"title":"Beauty and the Beast"}}]}}}},
{"_source":{"name":"Ariana Grande"},"inner_hits":{
"song":{"hits":{"total":1,"max_score":1,"hits":[
{"_source":{"title":"Beauty and the Beast"}}]}}}}]}}
Accessing a Child Document
The Elasticsearch REST API is going to change. Evaluate the respective versions. We have multiple mapping types enforce the need to address the type in the URL. To access a child document, we must know its parent and provide the routing information.
Search with multiple mapping types (Elasticsearch < v5.6):
GET music/song/1?routing=1
{
"_index": "music",
"_type": "song",
"_id": "1",
"_version": 3,
"_routing": "john-legend",
"_parent": "john-legend",
"found": true,
"_source": {
"title": "All of Me"
}
}
See below the example for current versions.
GET music-5_6/doc/3?routing=1
{
"_index": "music-5_6",
"_type": "doc",
"_id": "3",
"_version": 3,
"_routing": "1",
"found": true,
"_source": {
"song": "All of Me",
"artist_relations": {
"name": "song",
"parent": 1
}
}
}
Updating Child Documents
One of the significant benefits of a parent-child relationship is the ability to modify a child object independent of the parent. To update a document, we must also know the parent and provide the routing information.
For instance change the song name for the following song, because it is a remake of a previous version:
For version, less than 5.6 provide the mapping type.
POST music/song/2/_update?routing=ariana-grande
{
"doc": { "song": "Beauty and the Beast (2017)" }
}
POST music/song/3/_update?routing=ariana-grande
{
"doc": { "song": "Beauty and the Beast (2017)" }
}
For version greater than 5.6.
POST music-5_6/doc/5/_update?routing=2
{
"doc": { "song": "Beauty and the Beast (2017)"}
}
The song document is in the middle, but it does not affect the artist and the user-likes.
Aggregations
Dealing with parent-child relationships also adds complexity. You can also aggregate over child documents. Following full monty example could be a typical question in the Elastic Certified Engineer exam. We have two song documents for the song Beauty and the Beast. One is assigned to the artist John Legend and the other to Ariana Grande. Now we would like to know the count of user likes and see the user names that liked that song.
 Photo by Daniel Cheung on Unsplash
Photo by Daniel Cheung on Unsplash
GET music/_search
{
"query":{"bool":{
"must":[{"match":{"title":"Beauty and the Beast"}}],
"should":[{"has_child":{"type":"likes","query":{
"match_all":{}},"inner_hits":{}}}]}
},
"aggs":{"user_likes":{
"children":{"type":"likes"}}}
}
The response from Elasticsearch:
{
"took": 2,
"hits": {
"total": 2,
"hits": [
{
"_source": { "title": "Beauty and the Beast" },
"inner_hits": {
"likes": {
"hits": { "total": 1,"hits": [ { "_source": { "user": "Berte" } } ] }
}
}
},
{
"_source": { "title": "Beauty and the Beast" },
"inner_hits": {
"likes": {
"hits": { "total": 1, "hits": [ { "_source": { "user": "Emma" } } ] }
}
}
}
]
},
"aggregations": {
"user_likes": { "doc_count": 2 }
}
}
Summary
Using parent-child relationships in Elasticsearch is an advanced method. Use it only when needed. A parent-child relationship searches slower and has more needs for system resources. If you can, always upgrade at least to Version 5.6 - otherwise, your implementation will and upgrade to Version 6 breaks. Avoid multiple mapping types if you can. The time you invest now is handsomely rewarded in the future; otherwise, anticipate a major migration or upgrade challenge. One possible outcome could be to stay on the specific Elasticsearch version, which is IMHO unwise.
Parent-child relationships have their advantages. As long as you are aware of the tradeoffs like the physical storage constraint of parent and child document and added complexity, you can efficiently use it. Try to keep the relationships levels simple. Having more than 3 levels makes it hard to maintain.
Literature
Find below some official articles and reference documentation.