Automating Cloud Foundry Upgrades with Concourse CI
With the frequency of patch releases being available for Pivotal Cloud Foundry (PCF), it becomes inevitable to automate their roll out in any professional operations setup. The patch releases often contain security fixes that harden the deployment, but also lot's of bug fixes that are highly useful to roll out. Typically, operators need to not only upgrade a single Cloud Foundry environment, but have to operate and patch multiple deployments of Cloud Foundry.
Concourse CI is a highly versatile continuous as a thing-doer with a shiny UI (and great CLI!) that we can use to automate everything around the platform. Concourse features easy mechanics, controlled and reproducible builds as well as storing all configuration as code, which makes it a perfect candidate to automate upgrading Cloud Foundry. In case you don't have a Concourse deployment yet, make sure to read our blog post on deploying Concourse with BOSH.
This blog post was in parts presented at the Cloud Foundry Meetup Stuttgart in May 2019 during my talk Blasting Through the Clouds - Automating Cloud Foundry with Concourse CI.
What do we need actually?
Until recently, with pcf-pipelines there has been a project containing pipelines and tasks to upgrade and install PCF, but the project has now been deprecated in favor of Platform Automation. PCF Automation at its core is a collection of reusable tasks that can be plugged to a Concourse pipeline to suit individual upgrade process needs. While both projects have great ideas and useful task implementations, we have faced more requirements that a Cloud Foundry upgrade pipeline needs to meet.
Environment Support
Automation pipelines that are available usually focus on upgrading a single Cloud Foundry foundation. However, in a typical customer deployment we have several Cloud Foundry foundations that each need to be upgraded. As the foundations have different purposes and QoS agreements, the order of upgrades being applied is usually quiet clear. Let's take the following setup, for example:
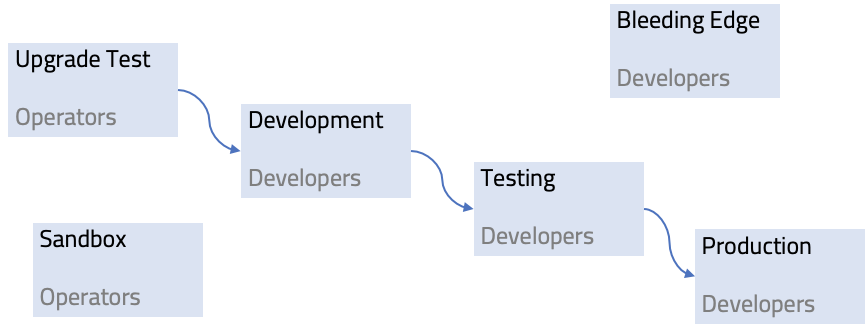
In this case, there are four environments where upgrades need to be applied in order, and two sandbox environments that serve other purposes and are not coupled to the upgrade flow. Operators need to be able to roll out upgrades to one environment, and if all goes well roll them out to the next environment.
Offline Support
Sometimes, a data center running Cloud Foundry has no internet access at all due to privacy concerns or regulations. Regardless of whether offline support is a requirement in your case, I definitely recommend that all your upgrade pipelines are fully offline. You don't want any external dependencies on your mission-critical infrastructure.
Having offline support is easily achievable with Concourse by using an S3-compatible storage solution that we use to store all artifacts flowing through the pipelines. With that S3 store, pipelines will never have to download tiles or stemcells on the fly, and you can rest assured that your pipelines will roll out the exact same bits on each of the environments.
A typical offline-first automation setup separates download pipelines and upgrade pipelines. That means we have some pipelines that populate the S3 storage with all required files (i.e. download them from Pivotal Network) and some pipelines that roll deploy these artifacts to a Cloud Foundry foundation.
Stemcell Handling
Stemcells as the base operating system used for all virtual machines deployed by BOSH is the heart of cloud security. All products deployed to a CF environment require a certain stemcell type (e.g. Ubuntu Xenial) typically along with constraints on the particular version of the stemcell to use (e.g. v170.14-170.56). Given those requirements it is inevitable to manage and upgrade pipelines during product upgrades.
However, stemcells can potentially be released more frequently as products, and when they contain important security fixes, we don't want the rollout of these stemcells to be coupled to product upgrades. Instead, we'd like to have a separate pipelines from which we can solely roll out a new stemcell, if available.
Really Bleeding Edge?
A lot of pipelines often neglect product version and simply opt for the latest version available. While bleeding edge is cool, it might not be desired to immediately deploy the latest version to production right after it becomes available.
Instead, what we actually want is more control over when which version is being deployed. This makes it an operators decision how the different environments are being patched.
Building a PCF Upgrade Automation
A key decision we have made is to store all assets in an S3 compatible store. By doing so, we can easily bring the solution into an offline environment where there is no direct internet access. As the S3 storage is our central point for storing and retrieving assets we first decided on a directory structure that allows us to manage multiple environments:
├── upload
│ ├── cf
│ │ ├── cf-2.4.1.pivotal
│ │ └── cf-2.4.2.pivotal
│ └── p-isolation-segment
│ └── p-iso-2.4.1.pivotal
├── info
│ ├── cf
│ │ ├── 2.4.1.yml
│ │ └── 2.4.2.yml
│ └── p-isolation-segment
│ └── 2.4.1.yml
└── installed
├── dev
│ ├── cf
│ │ ├── cf-2.4.1.pivotal
│ └── p-isolation-segment
│ └── p-iso-2.4.1.pivotal
└── prod
├── ...
The directory structure for the Cloud Foundry automation works as follows:
- upload: The upload directory contains the actual product files downloaded from the Pivotal Network organized in subfolders per product. There can be a pipeline downloading new versions from Pivotal Network and putting them here, or operators can simply upload new versions to this folder when they are available. The versions in here can then be used and deployed to all environments.
- info: For each of the uploaded products we extract metadata that we store in the
infofolder with the same layout as theuploadfolder. Metadata is being reused across different jobs throughout the pipeline and by caching it here we can speed up the pipeline by not repeating unnecessary computations. - installed: The
installedfolder contains a copy of the exact bits that have been deployed to a specific environment. In the example above there are two environments denoteddevandprod. Each of the environments contains a folder for each product installed in that particular environment.
Triggering a Cloud Foundry Upgrade
As an operator, I want to control which version of PCF is deployed to which environment and define at which time that will happen. For example in the following case, we have a Cloud Foundry deployment with some additional products that we want to upgrade to a new version:
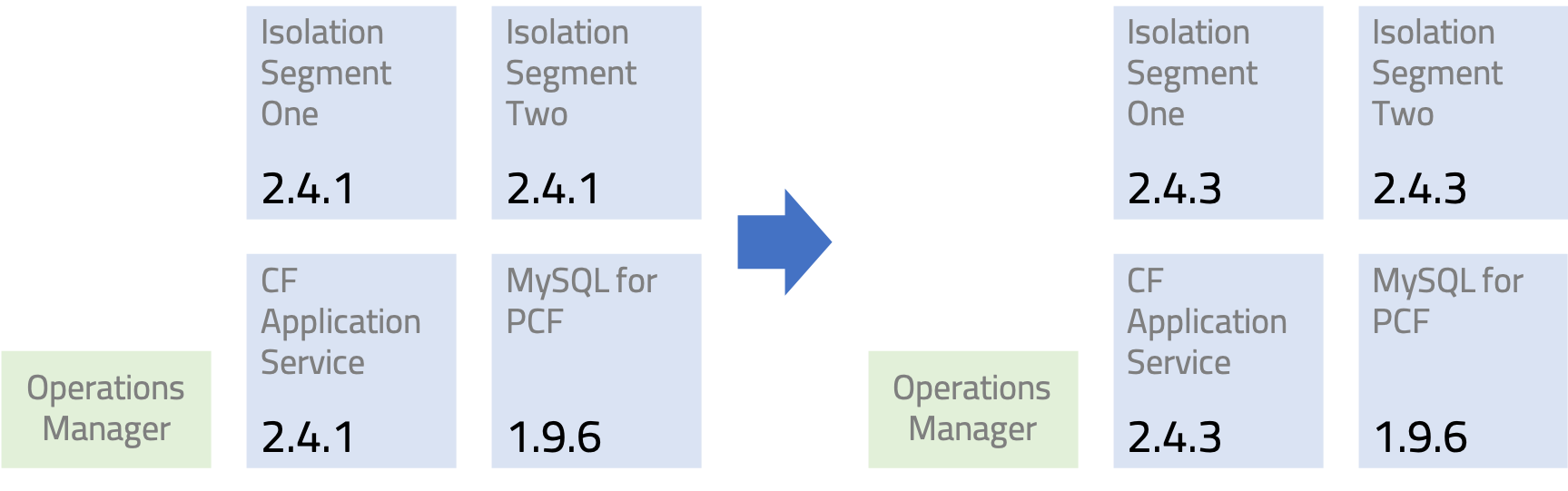
We can essentially describe the operators objective in a single YAML file, which turns out to be the format we use to trigger the Cloud Foundry upgrade pipelines:
# dev.yml: Deployment state before the upgrade
cf: 2.4.1
isoseg-one: 2.4.1
isoseg-two: 2.4.1
p-mysql: 1.9.6
And now to upgrade we can simply change the version numbers to the ones we want to upgrade to (note that we don't upgrade p-mysql):
# dev.yml: Environment state file to trigger the upgrade pipeline
cf: 2.4.3
isoseg-one: 2.4.3
isoseg-two: 2.4.3
p-mysql: 1.9.6
The file is stored in a Git repository and the Concourse upgrade pipeline is triggered from any changes to that file. That means that as an operator you simply need to update four lines in a YAML file, and commit and push to upgrade a whole Cloud Foundry environment to a new patch release.
What has been really important to use while building this solution is focusing on the Operator Experience (OX), as the operator will use the system all day long. But narrowing down platform upgrade triggers to a couple lines of YAML code does not only do a favor for operators, it also allows us to plug the different environments together, so that the operator could manually trigger the first environment, and if all goes well the update is applied to the other environments down the line by applying the Git diff to their environment state file. And on top of that, we have a clear Git history of when upgrades were performed and in which order.
The Upgrade Pipeline
The Concourse upgrade pipeline that performs the actual upgrade looks as follows:

The pipeline defines the following jobs:
- setup-installation: As a first step we need to make sure that the versions defined in the state file actually are a valid combination.
That means that we verify that the versions are actually available in our S3 store and that required stemcells are either already present or can be installed from the S3 storage.
Also, we make sure that it is impossible to accidentally upgrade to a lower version than installed.
Then, we actually move all product files that need to be applied from the
uploadfolder to theinstalledS3 folder of the respective environment. - upload-product: Here we upload all product files that need to be upgraded to the Operations Manager. If required, any missing stemcells are also uploaded to the Operations Manager.
- stage-product: This job stages all products that need to be upgraded.
- apply-changes: Finally, the changes are applied and the Operations Manager starts the actual upgrade process.
You might notice that there is no Concourse resource for product files - and that is correct. As resource versions can't be easily set in Concourse without modifying the pipeline we found it easier to fetch the correct version of the resources from within our tasks.
To support the above jobs we wrote custom Concourse tasks that usually iterate over all products that need to be upgraded and apply their respective job there. We haven't yet open-sourced those tasks, but we heavily use our pcfup Cloud Foundry automation tool from within the tasks. You may want to check out the scripts we wrote there as inspiration for your own tasks.
Conclusion
With our pipeline setup we are able to manage and upgrade multiple Cloud Foundry environments with all upgrade being orchestrated from some YAML files. For operators it thus becomes really trivial to apply patch upgrades.
There are still some challenges left, as Concourse is a great tool for running pipelines, but actually is really limited when showing what's really happening from a domain perspective. We'd love to have a dashboard that shows the state of the different environments and more contextual information, that just can't be part of what Concourse does. Oh well, seems like we need to think about building something there, too :-)