Building a Reverse Image Search with Elasticsearch
In a previous blog post I demonstrated how the vector datatype in Elasticsearch can be used to search words by their semantic meaning. In this post I will show how a reverse image search for paintings can be implemented using the same methods. Given a photo of a painting, we will use Elasticsearch to find other paintings which look similar.
To implement a similarity search by an abstract search criteria (such as the style of a painting), follow these three steps:
- represent documents as vectors
- index the documents and corresponding vector representations in Elasticsearch
- calculate similarity between a query document and documents in the index for scoring
These steps are elaborated in the remainder of this post.
What are vectors?
Note: You can skip this section if you are already familiar with vectors, cosine similarity and Euclidean distance.
A vector is a matrix that has only one row or column.
A vector can be represented as an arrow in two- and three-dimensional space.
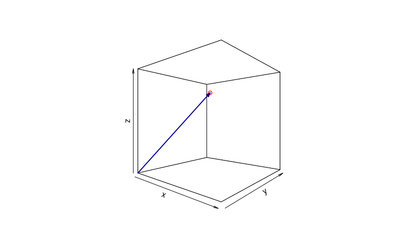
To measure similarity between vectors we can use cosine similarity or Euclidean distance. Cosine similarity measures the angle between two vectors, while Euclidean distance measures the distance between the points.
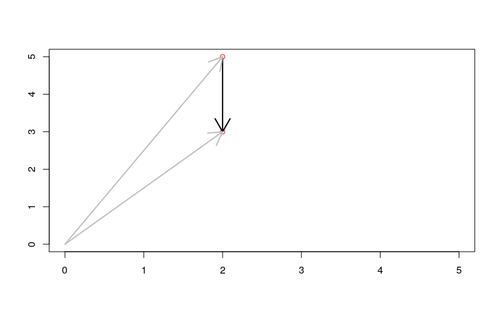
Euclidean distance takes into account the length of the arrow, while cosine similarity only captures the direction.
Both methods also work with higher dimensional vectors.
In higher dimensions we can represent a vector as a list of numbers:
(0, 0, 2, 3, 4, 1, 12, 4)
Both, Euclidean distance and cosine similarity, are available for use in painless script - the scripting language for queries in Elasticsearch.
See functions for vector fields for examples and explanations.
L2 norm (Euclidian distance) and L1 norm (Manhatten distance) have been added to painless script in version 7.4.
Step 1: Represent images as vectors
When searching paintings we want to represent the style of paintings in the vectors. The process of reducing high-dimensional data (such as a million pixels of an image), into a lower-dimensional feature (such as a vector with 512 dimensions) is called feature extraction.
While there are various methods to perform feature extraction on images, I chose to train a convolutional neural network to classify different styles and genres of paintings. The trained model was used to extract vector representations from an intermediate network layer. The extracted vector representation captures part of the original image and part of the learned feature which helps classifying the style and genre.
This 3D-visualisation of a convolutional neural network can help to get an understanding of how this works under the hood.
When using Keras or TensorFlow 2 with the Keras API, we can take a trained model and define a new model which uses intermediary layers as its output to accomplish this:
from keras.models import Model
intermediate_layer_model = Model(
inputs=classification_model.input,
outputs=['dense_layer1', 'dense_layer2']
)
vector_outputs = intermediate_layer_model.predict(batch_of_images)
When feeding input images into the intermediate_layer_model, we get vector representations from dense_layer1 and dense_layer2 as outputs instead of classification results from the original model.
Step 2: Index vector representations in Elasticsearch
First, an index mapping with a dense_vector type must be created.
{
"mappings": {
"properties": {
"Painting": {
"properties": {
"title": {
"type": "text"
},
"common512": {
"type": "dense_vector",
"dims": 512
}
}
}
}
}
}
Afterwards we can use our image vectorizer to create vector representations for all paintings in our dataset. The created vector representations can then be stored in the Elasticsearch index.
Step 3: Use script score queries to find similar images
Thanks to the predefined functions for vector fields in painless script, getting images with similar style is only a script score query away:
{
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "1 / (l2norm(params.queryVector, doc['common512']) + 1)",
"params": {
"queryVector": [0.1, 0.2, 0.4, 0.1, 0.0, ...]
}
}
}
}
}
The l2norm function calculates the Euclidean distance between a query vector and the vector of the indexed documents.
The result is inversed so that higher similarity results in higher scores.
The result of the script is used for scoring to get the most similar images from the index.
Results and source code
Using this simple setup we get a gallery which allows browsing paintings by similarity.
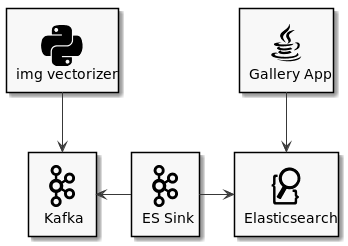
The image vectorizer submits paintings and vector representations to a Kafka topic. The Kafka sink connector stores new paintings in Elasticsearch as soon as they were processed so that they become available for the gallery app.
Below are samples of the built gallery application in action. The first image is the query image, the row of images below are the results of the Elasticsearch query.



The source code for this setup can be found on GitHub: github.com/schocco/img-similarity-search
The dataset used for the project can be found on Kaggle: kaggle.com/c/painter-by-numbers
Limitations to consider for production use
The dense vector datatype is marked as experimental and stored vectors shouldn't exceed 1024 dimensions in version 7.5.
Document scoring with script functions is expensive because the score needs to be calculated for every document. Such queries should be used together with filters to limit the number of documents for which scores need to be calculated.
You should run experiments to see which similarity function works best for your data.
You should also try to reduce the number of dimensions with a dimensionality reduction method like t-sne
to decrease computational complexity at query time.