Enterprise Cloud Foundry Buildpack Management with Concourse
For automating a Cloud Foundry installation often the automation tool Concourse is used. In the recent blog post Deploying Concourse as BOSH Deployment Fabian Keller described how to deploy Concourse. With this Concourse installation, you can do a lot of different Cloud Foundry related topics. Besides updating Cloud Foundry itself, another possible use case is to upgrade the buildpacks, which is shown in this blog post.
Motivation
The pcf-pipelines, part of Pivotal Open Sources PCF tools, provide a way to upgrade the buildpacks. This pipeline is really great for upgrading buildpacks in a sandbox foundation, but not in a complex infrastructure. In our scenario, we have had two different Cloud Foundry foundations. The schema shown in this blog post is also adaptable to a single foundation or foundations of any size.
For us, it was important, that we are able to install the buildpacks in a fully automated way without human interactions. In addition, we would like to provide a possibility for the engineering to test the buildpacks before they are going to production or even to the first test foundation. On the other hand, we would like to stay flexible in case of security updates, therefore, it should have a side track. Also, we would like to restore an old buildpack version, in case the buildpack was not working. Last, we would also like to inform the engineering about new buildpacks through a Slack channel.
Buildpack Lifecycle Management
For each foundation, we have had the buildpacks which are available from PCF by default.
Those buildpacks are managed by Cloud Foundry itself, so we introduced new buildpacks, prefixed with custom_ to avoid overriding by Cloud Foundry.
You might want to add those buildpacks with one of the first positions inside PCF, to ensure that they are used as default buildpack.
In addition, to give the chance to test buildpacks before, we introduced the _latest suffix similar to the pcf-pipelines.
The result was, that on our test foundation we have had the following buildpacks (sorted like in Cloud Foundry):
custom_(name-of-buildpack)The default buildpack, provided by our buildpack pipeline. Updated every first Monday of a month at 9 am.(name-of-buildpack)Buildpack provided by PCF, not managed by the buildpack pipeline.custom_(name-of-buildpack)_latestLatest buildpack added every Monday in the month at 4 pm.
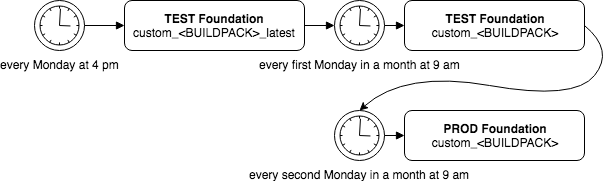
In case we have a new buildpack, that would first visible with the _latest suffix.
Every developer is able to test this buildpack periodically, but it is not enforced.
In addition, this latest buildpack gets tested by a Concourse task directly after the deployment, therefore a test app is deployed.
The reason was, that we also have buildpacks which are built by us and we would like to ensure that all custom modifications are available.
On the first Monday in a month, this buildpack will get automatically renamed to the custom_ buildpack.
This makes now the buildpack to the default buildpack.
Since we have had an additional separate production foundation, we decided to deploy one week later this buildpack to production.
In that case, the engineering is still able to fix issues in production, even if the new custom_ buildpack breaks their deployment.
Furthermore, if we have larger issues with the buildpack, we only need to restore the old buildpack in one foundation.
Concept for Buildpack Deployment
Concourse is using YAML files to configure the tasks. Since we have a couple of different buildpack, it does not scale to write YAML content for all of them. On the other hand, we have a couple of different parts for different buildpacks. Normally, buildpacks are either coming from the Pivotal Network, in case we have Pivotal Cloud Foundry, or we need to build them on our own. Then we need to specify a test application with an instruction on how to deploy this application. Last but not least, we have for different buildpacks, of course, different names.
Directory Structure
For our solution, the following directory structure suited well:
- buildpacks/
- go-buildpack.yml
- java-buildpack.yml
- ...
- tasks/
- promote-buildpacks-on-prod-only-monday/
- task.yml
- task.sh
- promote-buildpacks-on-test-only-monday/
- ...
- push-app/
- ...
- promote-buildpacks-on-prod-only-monday/
- templates/
- base-template.yml
- buildpack-template.yml
- additional/
- spring-music.yml
- build-pipeline.sh
The first directory buildpacks/ is a YAML based configuration folder.
We have one small YAML file which shows us the specific part for this buildpack.
An example would be for the go-buildpack.yml:
# buildpack names
buildpack-name: go-buildpack
human-readable-name: Go Buildpack
cf-latest-buildpack-name: custom_go_buildpack_latest
cf-buildpack-name: custom_go_buildpack
# get the buildpack from:
input-resource-type: pivnet
input-resource-source:
api_token: ((pivnet-token))
product_slug: buildpacks
product_version: Go*
# buildpack patterns:
buildpack-regex: go_buildpack-cached-(.*).zip
buildpack-ls: go_buildpack-cached-*.zip
# test the buildpack with:
test-app-type: git
test-app-source:
uri: https://github.com/cloudfoundry-samples/test-app.git
branch: master
test-app-passed: []
We have the different names of the buildpack, either user readable or the internal name.
In addition, there are two names to specify the name of the deployed buildpack.
Afterward, we have the input-resource with its configuration.
Since we are storing all the buildpacks between the steps in a S3 bucket, we need a regex and a ls parameter to search the buildpack.
There, we have a couple of parameters to specify the test-app.
Since we need to preprocess the test-app for example for Java, we can add test-app-passed to specify additional tasks.
Those can be placed in the additional/ folder.
The tasks/ directory specify some of the custom Concourse tasks we have.
Those are shell script based tasks, which are outsourced for an improved readability.
The templates/ directory provides the templates for the buildpack and the remaining pipeline.
Those templates are not specific for a buildpack.
All configuration is either through the buildpacks YAML files or variables which are coming for example from CredHub.
The additional folder is to provide additional scripts. In our case that was necessary to build the Spring Music app before we are able to push the app.
Last we have the build-pipeline.sh.
That's a small bash script which is generating the complete pipelines which are ready for deployment.
Build the Pipeline
The core of this approach is a lot of YAML files.
But all of the YAML files need to come together to deploy them.
Therefore there is the build-pipeline.sh file.
This bash script is taking the base-template.yml file:
RESULT_FILE=$(mktemp)
cat templates/base-template.yml > $RESULT_FILE
Afterward, it is going to build the specific part for each buildpack.
Therefore it is using bosh interpolate to combine the variables with the buildpack-template.yml:
for vars in $(ls -1 buildpacks/*.yml); do
TEMP_FILE=$(mktemp)
echo "Buildpack: $vars"
bosh int templates/buildpack-template.yml --vars-file=$vars > $TEMP_FILE
Those combined template variables can be then merged to the already existing template in the $RESULT_FILE.
Therefore, there is a handy tool called spruce.
Besides the simple merging of fields which are additional, it also supports array merging in a couple of different ways:
RESULT_TEMP_FILE=$(mktemp)
spruce merge $RESULT_FILE $TEMP_FILE > $RESULT_TEMP_FILE
mv $RESULT_TEMP_FILE $RESULT_FILE
rm $TEMP_FILE
done
Now we have the complete pipeline for running the buildpacks. But for the Java buildpack, we might like to add a procedure to build the app before the test deployment. So we need to merge the custom code as the last step:
for job in $(ls -1 additional/*.yml); do
echo "Job: $job"
RESULT_TEMP_FILE=$(mktemp)
spruce merge $RESULT_FILE $job > $RESULT_TEMP_FILE
mv $RESULT_TEMP_FILE $RESULT_FILE
done
Finally, let's rename our pipeline to a more proper name:
mv $RESULT_FILE buildpack-installation-pipeline.yml
This is the complete build process and how all the different files fit together. Since we now have the buildpack pipeline, we can use fly to deploy it to Concourse.
Challenges During Writing the Template
The remaining steps are independent of the resulting approach when the buildpacks are installed.
The approach itself is described in the base-template.yml and for the buildpack-template.yml.
In our case, the buildpacks are installed on the first Monday in a month on the test foundation and one week later on production foundation.
Unfortunately, it's not possible to specify "first Monday in a month" with a cron expression.
You might think that would be possible by specifying the day of the month and the day of the week.
But there is one exception of the and-pattern in cron rules if you specify those two, it is an or.
Therefore, the resolution was to trigger a task every day between the first and the seven and check in addition, if it's a Monday.
Unfortunately, this resource has to fail in the case, it's not Monday since otherwise, it would need to return the result from before and skip the new result.
To avoid a failing task inside the pipeline, since this would cause trouble during deployment of for example security patches, this task was excluded from the main pipeline.
The result here is, that this task is only used to trigger other tasks with the fly cli.
To test an additional result is a list of the upgraded buildpacks since we would like to install them one week later on production.
The production task is similar, but it is using the output of the test to determine the buildpacks. Those two tasks are easy to see on the dashboard since most of the time they are red. There is only one chance for both of them to be green if the month starts with a Tuesday.
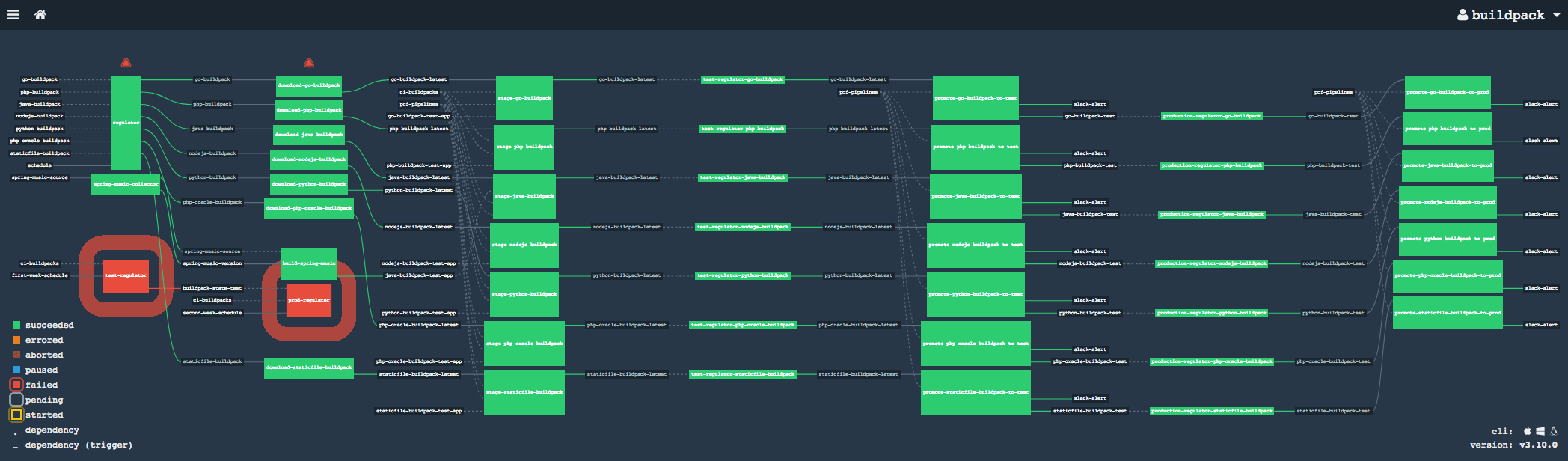
There are a couple of other tasks in the dashboard visible:
regulatorRegulates the installation of the_latestbuildpack.download-...Downloads the specific buildpacks from the given resource, either PivNet or S3.stage-...Stage the buildpack on the test foundation as a_latestbuildpack and test it.test-regulator-...Manual trigger by thetest-regulatoron the first Monday.promote-...-to-testPromote the buildpack from_latestto the regular buildpack.prod-regulator-...Manual trigger by theprod-regulatoron the second Monday.promote-...-to-prodInstall the buildpack on production.
Conclusion
Concourse provides a flexible way to build fully automated pipelines.
Furthermore, it is possible to install buildpacks in a controlled foundation and separately for different foundations within a test period in between.
With YAML files there is a flexible way to build pipelines.
Especially in combination with spruce and bosh interpolate there a rich possibility to write a flexible pipeline build script.
The complete project can be checked out at GitHub.